
本文主要列舉了一些我在區塊鏈產品設計過程中,遇到的與區塊鏈相關的常見問題和處理方案,適用於準備或初入區塊鏈行業的產品經理閱讀。本文中列舉的處理方案並不是唯一的,如果大家有其他方案,或遇到了其他的問題,歡迎留言討論。

一、上鏈數據處理
1. Hash
一般的,出於以下原因,我們無法在區塊鏈上存儲數據的原文:
- 數據隱私;
- 避免因數據量過大,加重全節點的存儲負擔;
- 礦工可能分佈於世界各地,假設北京的礦工廣播了一個高度為100的新挖出的區塊(命名為區塊100A),受網速影響,位於北京的另一位礦工和位於非洲的礦工接收到這一區塊的時間必然不同。區塊越大,非洲的礦工接收到區塊100A的時間越晚。這就導致了非洲的礦工可能會在高度為99的區塊的基礎上繼續挖礦,進而挖出了區塊100B並廣播,此時就出現了有競爭關係的兩條分叉,分叉A和分叉B,直到新的主鏈被選擇。這進一步導致了在未被選擇為主鏈的分叉上挖礦的礦工所做的工作均作廢,造成了資源的浪費。
出於上述原因,普遍做法是在區塊鏈上存儲數據原文的Hash值。基於Hash演算法的特點,數據原文均會被轉換為固定長度的字元串,且無法通過Hash值反推出數據原文,簡單有效地避免了上述問題的發生。
當然,這一做法也有其局限性,即只存儲Hash值的區塊鏈,只能用作數據在某一時刻的存在性驗證,而無法替用戶存儲數據原文。數據原文需由用戶自行保管,或交由第三方機構保管(可能面臨數據被篡改而無法通過驗證的風險)。
2. Merkel Proof
在日常工作中,我們可能會面臨這樣一種情況:一條數據包含A、B、C、D四個欄位,此時如何將這條數據上鏈呢?
簡單的將欄位A、B、C、D連接並進行Hash是一種方案,但對於某些場景,比如應聘者要將這條數據分享給用人單位,但出於隱私考慮,只想分享欄位A、B的數據原文,而不想分享欄位C、D的數據原文,在這一場景下,只對數據進行Hash計算並上鏈,顯然無法滿足這一需求。
此時,一種可行的方案是基於Merkel Proof,使用各欄位計算出Merkel Root Hash,並將該Root Hash上鏈。Merkel Root Hash的計算過程示意見下圖。
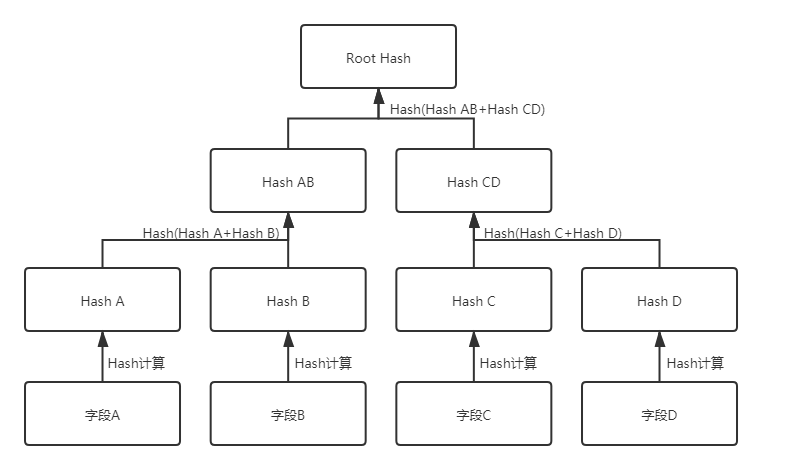
當用戶在分享數據時,願意展示給他人的欄位顯示為數據原文,不願意展示給他人的欄位顯示為Hash值,根據Merkel Proof,拿到這條數據的人依然可以計算出Merkel Root Hash,並在區塊鏈上驗證數據是否未被篡改。示意如下圖:
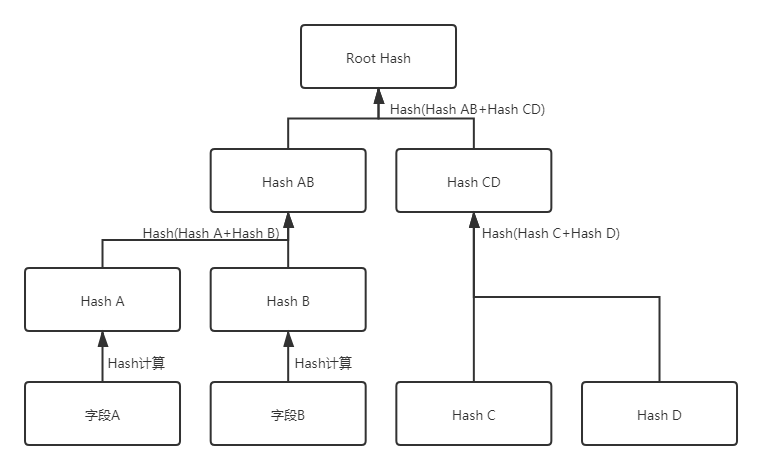
應用Merkel Proof除了可以解決涉及隱私的數據分享的問題外,還可以大幅降低上鏈數據的數量,間接提高TPS,如果數據上鏈是在如以太坊等公鏈,還可以大幅降低上鏈成本。
例如,有100條數據需要上鏈,通過Merkel Proof,可以將這100條數據計算為一個Merkel Root Hash。
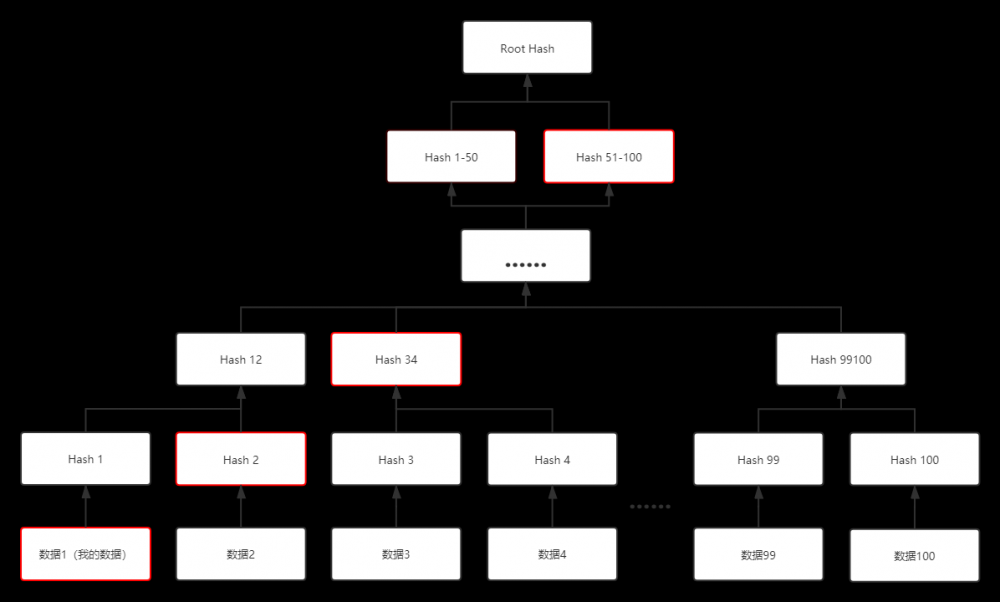
缺點在於,若用戶自行保管數據,除了要保管自己的數據外,還要保管跟自己的數據相關的數據Hash,增加了用戶需要存儲的數據量。
示意如下圖,用戶需要保管紅框中的數據。
二、私鑰管理
私鑰管理目前常用的有四種模式:
1. 不為用戶生成公鑰和私鑰
用戶在簽名交易(數據上鏈)時,由平台使用統一的私鑰進行簽名。
優點:用戶學習成本很低;開發成本低;用戶不需要擔心私鑰丟失問題。
缺點:由於所有數據均使用一個私鑰簽名,無法在區塊鏈上區分執行數據上鏈操作的用戶;過於中心化的處理方式,導致用戶有可能質疑上鏈數據的真實性;平台將承擔重大的安全責任。
2. 為用戶生成公鑰和私鑰
私鑰由平台統一保管,用戶在簽名交易(數據上鏈)時,由平台直接使用用戶私鑰簽名。
優點:用戶學習成本很低;開發成本低;用戶不需要擔心私鑰丟失問題;可以在區塊鏈上分辨出數據是由哪個用戶執行的上鏈操作。
缺點:過於中心化的處理方式,導致用戶有可能質疑上鏈數據的真實性;平台將承擔重大的安全責任。
3. Keystore
為用戶生成公鑰和私鑰。其中私鑰由用戶自行設置密碼加密,並由平台統一保管。用戶在簽名交易(數據上鏈)時,需輸入密碼解密獲得私鑰並簽名。
優點:用戶學習成本較低;可以在區塊鏈上分辨出數據是由哪個用戶執行的上鏈操作;在某種程度上,可以認為是去中心化的數據上鏈方式。
缺點:開發成本高;用戶多了一步設置密碼操作,以及在每次執行上鏈操作時多了一步輸入密碼的操作;由於平台沒有保存用戶私鑰的原文,一旦用戶丟失或忘記用於加密私鑰的密碼,後續該用戶上鏈的數據的真實性將無法保證,甚至無法執行上鏈操作。
4. 為用戶生成公鑰和私鑰,由用戶自行保管私鑰。
優點:開發成本很低;可以分辨出數據是由哪個用戶執行的上鏈操作;完全去中心化的數據上鏈方式。
缺點:用戶學習成本高;用戶每次執行上鏈操作時多了一步輸入私鑰的操作;由於平台沒有保存用戶私鑰的原文,一旦用戶丟失或忘記私鑰,後續該用戶上鏈的數據的真實性將無法保證,甚至無法執行上鏈操作。
具體採用哪種方式,需要根據去中心化要求、安全、成本、開發能力等多方情況綜合考慮。
三、私鑰的丟失處理
在第三節列舉的私鑰管理方案中,無論私鑰由平台保管還是用戶保管,都可能涉及遺忘私鑰或私鑰的加密密碼的情況。在傳統互聯網產品中,若用戶忘記密碼,可以通過手機號、郵箱等方式重新設置密碼,但對於區塊鏈產品,無論是私鑰還是私鑰的加密密碼,都不能簡單的使用傳統的忘記密碼流程進行處理。
目前一種可行的處理方式是,在區塊鏈上的智能合約中,記錄用戶信息、用戶公鑰地址、公鑰地址的有效狀態(包括有效和實效)和失效時間。其中公鑰地址為與用戶私鑰唯一對應的公鑰的Hash值,有效狀態和失效時間用於在數據驗證時,驗證數據的有效性(在第七節將具體說明)。
當用戶遺忘私鑰或私鑰的加密密碼時,可以為其重新生成一組公私鑰對,並把新的公鑰地址寫入智能合約,並與用戶信息關聯,同時將舊公鑰地址的有效狀態改為失效,並寫入失效時間。
可見,這一方式通過在區塊鏈上為用戶關聯多個公鑰地址,解決了用戶遺忘私鑰或私鑰加密密碼的問題,同時還能標識出公鑰的擁有者,便於確定執行上鏈數據的用戶。
四、用戶的自我數據保管
傳統的互聯網產品,用戶數據由平台中心化保管,這導致了用戶隱私、數據安全等問題,且用戶自己產生的數據沒有為用戶創造出價值。
而在區塊鏈產品中,為改變這一情況,需要允許用戶導出自己的數據。有一個原則是,用戶導出的數據,需要能不依賴於任何中心化的驗證平台,獨立在區塊鏈上驗證該數據是否存在,這就要求導出的文件中必須包含所有數據驗證所需的欄位,如數據原文、Hash演算法等,這些數據通常以json文件的形式存。
同時,考慮到json文件的可讀性較差,導出的數據還可以包含易讀的明文數據(比如用戶的原始數據文件,如圖片或文檔)。通常會將這些導出的數據打包為一個壓縮包供用戶下載。另外,為提升用戶體驗,壓縮包中還可以帶有使用說明,以說明壓縮包中各文件的作用,及數據驗證方法。
五、數據刪除和編輯
在傳統的互聯網產品和軟體產品中,一般都允許用戶刪除和編輯自己的數據。但對於區塊鏈產品,如果僅對資料庫進行操作,而不在區塊鏈上採取對應措施,會導致已刪除或編輯前的數據存在於區塊鏈上,且能夠通過存在性證明,進而產生安全隱患等。
一般來說,對於刪除的數據,需要重新在區塊鏈上發起一筆交易,除帶有該數據的Hash等常規信息外,還需要額外帶有數據撤銷標識。在數據驗證時,如果待驗證的數據所在交易中,存在撤銷標識,則意味著這條數據已被刪除,驗證將無法通過。
對於編輯的數據,相當於在區塊鏈上發起兩筆交易,一筆交易用於撤銷編輯前的數據,另一筆交易用於將編輯后的數據上鏈。
一般來說,用戶自身不具備通過區塊鏈驗證數據是否存在且未被篡改的能力,而是需要通過中心化的平台提供的驗證能力進行驗證,這裡就涉及到平台需要驗證哪些內容。
下面列舉一些較為通用的驗證項(不代表先後順序),可根據實際需要選取:
- 獲取待驗證數據中,代表該數據所在交易的標識,並使用該標識獲取區塊鏈上的相應交易詳情;
- 從交易詳情中獲取簽發交易的用戶的ID,並使用用戶ID和交易標識檢查該交易是否已被撤銷;
- 驗證數據相關的智能合約是否未被篡改;
- 從交易詳情中獲取簽發該條數據的用戶的公鑰地址,並在用戶管理智能合約(參見第四節)中,檢查該公鑰地址是否存在且是否未過期;
- 檢查待驗證數據的格式是否符合平台規範;
- 檢查待驗證數據的哈希值是否與區塊鏈上的交易詳情中記錄的哈希值一致。