
編輯導語:DIKW金字塔,也被稱為DIKW層次結構、智慧層次結構、知識層次結構、信息層次結構和數據金字塔。近年來,AI已經影響著我們生活的方方面面。本篇文章中作者圍繞AI沿著DIKW金字塔向上攀爬,將會帶來怎樣的變化展開了一系列的講述,對AI感興趣的朋友們一起來看一下。

你可能沒聽說過DIKW金字塔,但你一定曾被按在這座塔的鄙視鏈上摩擦過。
曾有某個遊戲主播形容自己的預判:觀眾只看到了第二層,想到了第一層,實際上我在第五層。
於是,網友們形容一些讓人意想不到的操作,「這波啊,這波是在大氣層」。這種說法雖然有些戲謔,但還真有點科學道理。
DIKW金字塔,是一個關於人類理解、推理和解釋的層次結構,分別是:數據(原始的事實集合)、信息(可被分析測量的結構化數據)、知識(需要洞察力和理解力進行學習)、智慧(指導行動)。
站在DIKW金字塔尖的人,相當於全部通關的頂級選手,掌握了數據、整理成信息、理解為知識、轉化成智慧,才能讓行動如有神助。
足智多謀如諸葛亮,錦囊妙計用的那叫一個信手拈來,絕對是「站在大氣層的男人」。
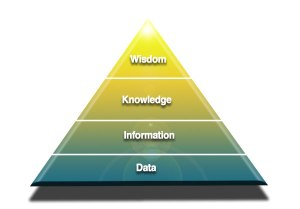
DIKW金字塔適用於人,也適用於AI嗎?答案是肯定的。
如果AI也有鄙視鏈,那麼基於數據的AI,一定會被基於知識的AI碾壓。
這是因為,AI Is A Knowledge Technology,AI就是一種由知識驅動的技術。
因此,從初級人工智慧向高級人工智慧、通用人工智慧發展的過程,也是一個攀爬DIKW金字塔的過程。
近年來,AI領域的諸多學術力量、產業力量,從強調「數據出奇迹」的蠻力計算,向著「知識金字塔」的更高層級進發,推動知識計算引領AI應用的未來潮流。
可以說,我們正處於一個向基於知識的AI過渡的關鍵階段。
AI已經影響著你我生活的方方面面,所以有必要來聊一聊,AI沿著DIKW金字塔向上攀爬,將會帶來怎樣的變化?
一、回歸的鐘擺:理性主義的復興
將知識運用在機器智能當中,並不是什麼新鮮事。
早在上個世紀,人類就開始了探索知識計算的步伐,並廣泛應用到工作和生活當中。
AI誕生的那一刻起,就是理性主義和經驗主義兩大流派的交相輝映、此消彼長。
它們的共同之處,都認為機器智能首先要擁有知識,知識是智能的核心;分歧在於,對於知識的理解和獲取途徑不同。
而伴隨著這兩大流派的發展,知識與AI的結合,也就表現為兩種方式。
一種是理性主義的結合,人提供知識,機器負責計算。
理性主義認為人的智能是先天遺傳的,要實現機器智能,就要理解人腦的運行機制,將這個東西總結成知識,再由人來告訴機器怎麼做。
典型應用就是專家系統。
人類專家總結出知識,計算機根據專家系統知識庫進行學習,這種方式可解釋性非常高。
從1968年世界上第一個專家系統——化學專家系統DENDRAL研製成功之後,針對某個單一領域、模仿專家進行推理分析的早期專家系統開始流行起來,廣泛應用於工農業、醫療、氣象、交通、軍事等眾多產業計算場景之中。
不過,專家機只能在一些特定領域發揮作用,建構成本非常高。並且,受限於專家的認知上限,如果人都沒有找到那個知識,或者表述不出來的話,機器就更不可能學會了。
於是從九十年代到現在,另一種AI與知識的結合模式就佔據了主流,那就是經驗主義。
由人手工打造一個分類器,開發人員不必提前知道答案,機器可以不依賴那些人類專家描述不出來、「只可意會不可言傳」的知識,按照自己的運作機制,從數據中來挖掘知識,通過大規模數據訓練出模型參數,表現出超過人類的智能。
最具代表性的就是深度學習。依靠強大的數據、算力和神經網路,谷歌大腦可以不需要人類的幫助,在不知道「貓」這個詞的前提下,通過訓練將數據轉化為知識,看過數百萬張圖片后,自己提煉出貓的基本特性,知道貓是一種毛茸茸的(此處省略一堆形容詞)生物,然後成功在一堆照片中識別出貓。

基於龐大的數據,AI雖然並不真正理解和掌握相關知識,也就是「知其然不知其所以然」,不可能真的取代人類專家,但可以將複雜的模式識別問題分解成更簡單的模式識別問題,在一些特定任務中表現得比人類更好、效率更高,取得了長足的發展。
深度學習也被視為經驗主義的高峰,成為推動第三次AI浪潮的核心。
但是,基於數據的AI,和基於知識的AI,還是有本質區別的。
著名的莫拉維克悖論,早就指出過這個問題,因為機器無法像人一樣將隱性知識融入思想和行動之中,形成高階智慧,所以成了邏輯的巨人、常識的矮子,在一些困難的問題如下圍棋上能超越人類,但在很簡單的認知問題上,表現反而不如四五歲的人類小孩兒。
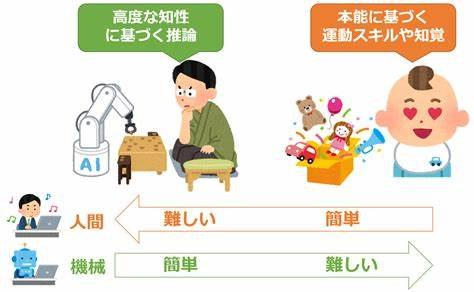
而解決思路之一,就是理性主義所推崇的,讓機器能夠如同真正的人類一樣理解知識並進行思考。
就像丘吉在《鐘擺擺得太遠》(A Pendulum Swung Too Far)所預測的那樣,AI已經偏離經驗主義太遠,將來回歸理性主義的速度就會越快,理性主義復興的步伐正在到來。
二、產業的呼喚:數智化浪潮與知識之光
或許你會認為,經驗主義和理性主義,只是學術界的流派之爭,跟普通人和工業界沒什麼關係。
實際上,在產業智能化的浪潮中,有越來越多的行業和組織,開始呼喚基於知識的AI,這是因為——模型設計階段,需要基於知識的理解。
我們知道,AI已經開始走出實驗室和象牙塔,走向千行百業,開始與物理世界和生物世界結合,而這些領域的數據並不是全部由1和0所構成。
比如AI預測蛋白質結構,每個蛋白質都不是一個簡單的圖像數據,它的背後是有具體意義的。
不同的分子關係如何、怎樣相互作用、靠什麼原理組合在一起等,有一整套生物學邏輯和知識體系支撐的,如果缺乏對藥學知識的了解,用純數據驅動的方法來設計模型,很可能做出來的模型無法發揮效用。
因此,想要AI模型真正能夠在產業端發揮價值,要結合實際工作的機理模型、專家知識等,轉化為AI可理解、可處理、可分析的數學語言。
1)模型訓練階段,需要基於知識的數據
在產業AI中,數據中往往存在大量的信息,也就是沒有或無法被表徵的知識,往往體現為專家經驗或師徒傳承。
想要訓練出效果更好的產業模型,不僅需要大量、完備的數據,還要能夠精準描述出數據之間的知識關係,這樣才能夠從數據中挖掘出更多有用的知識。
就拿我們日常都會碰到的推薦演算法來說,傳統的推薦演算法是用戶喜歡什麼就推薦什麼,很容易陷入信息繭房。
而國內某科研團隊,將食品營養科學的知識圖譜與推薦演算法相結合,根據用戶反饋數據,比如點擊量、興趣偏好、身體數據等等,結合健康知識來進行組合搭配與推薦。基於知識的數據,能夠幫助打造高質量、更懂人性的演算法。
就拿前面提到的推薦系統來說,相比不斷迎合用戶的演算法,提供了一種既滿足口味喜好、又符合健康管理要求的選擇。
再設想一下,如果AI能夠將外賣配送員的行為數據與人的常識性知識結合到一起,或許無限擠壓配送時間導致的內卷困境,也有望被解決了。
2)模型落地階段,需要基於知識的信任
AI模型落地應用,在很大程度上取決於其可靠性:一是可信度,結果是否被人所信任,深度學習受限於可解釋性問題,在醫療等專精領域不如人類專家被信任;二是可靠性,能否在被干擾的情況下也能表現出較好的性能,也就是解決魯棒性問題。
中科院院士、清華大學人工智慧研究院院長張鈸教授曾提出,在產業落地應用的人工智慧,需要符合五個條件:豐富數據或知識、完全信息、確定性信息、靜態環境、特定領域或單一任務。
這五個條件只要有一個不滿足,AI產業化落地都非常困難。而改變困境的思路之一,就是知識計算,讓AI系統能夠讀懂知識、學會常識推理,從而讓模型變得可信任、高可靠。
此前,谷歌為了提高搜索引擎結果的可信度和說服力,就將NLP與知識圖譜相結合來進行學習。
如果搜索者發現一些文章提到「XX曾在中國工作過」的信息,這些信息與知識庫融合在一起,顯示出XX曾為對華貿易委員會工作,而該組織在北京設有辦事處,那麼「XX曾在中國工作過」的可信度就會大大提高。

同樣,如果自動駕駛系統從大規模文本信息中提取並學習到一些出行常識,比如「大卡車擋住了前方的視線,應該小心一點,說不定突然過來一個人就可能撞到」,對常識性知識的理解無疑會大大增加人們對自動駕駛安全性的信心。
3)模型應用階段,需要基於知識的計算
當前產業智能化的一大瓶頸是高成本的算力。龐大的深度神經網路系統需要大量計算資源來處理複雜任務。
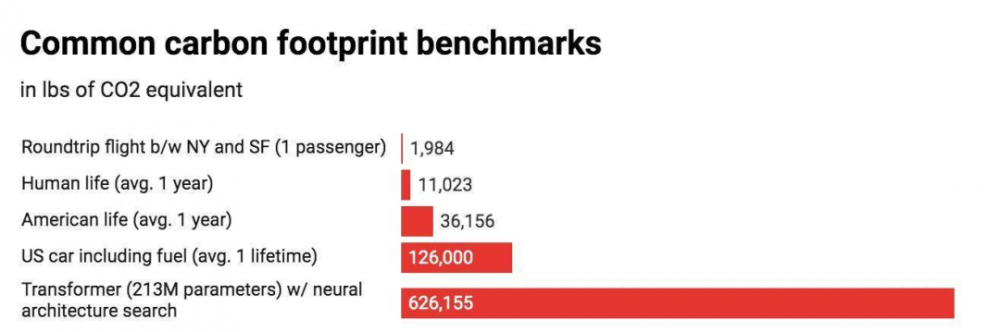
一份來自馬薩諸塞大學的研究顯示,常見的幾種大型AI模型,訓練過程會排放超過626000磅二氧化碳,幾乎是普通汽車壽命周期排放量的五倍。
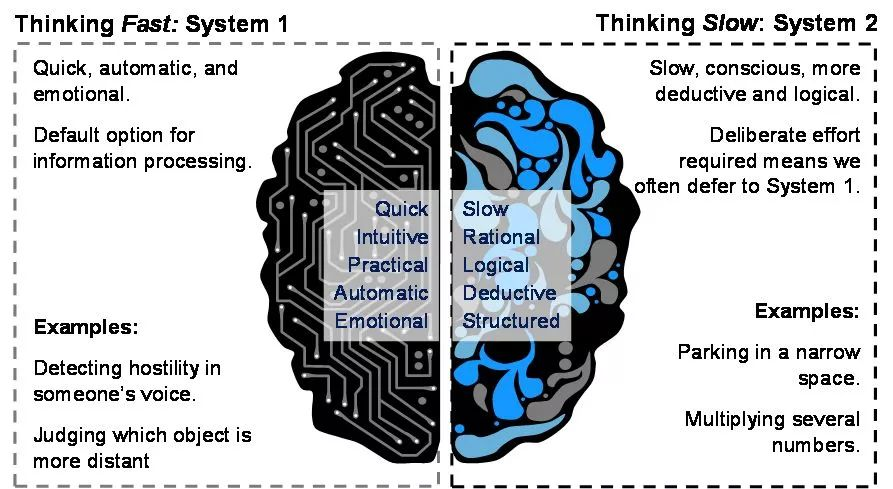
拉踩一下,人類在思考(也是一種知識計算)時就十分節省能耗,心理學家卡尼曼在《思考,快與慢》中就提出,人腦既可以通過系統2進行較慢的理性思考,也可以經由系統1,基於已經內化的知識,實現無意識的、近似於肌肉記憶的快速運算,大腦能量消耗極少。
未來,打造基於知識的AI模型,如同激活腦區一樣,將成為綠色計算的重要方法,保證產業智能的可持續發展。
不難發現,行業知識與AI計算的結合,既是理論上技術發展的必然階段,也是事實上產業AI化所不可或缺的一步。
作為一種致用技術,AI只有真正接納並融合行業知識,讓計算與知識轉變成新時代的生產力,才能凝結出技術的長期價值,推動第三次人工智慧浪潮繼續向前奔涌。
三、艱難的攀爬:從數據層到知識層總共分幾步?
拋開應用條件談技術前景的都是「畫餅」,基於知識的AI同樣少不了前提條件。需要具備至少幾個特徵:
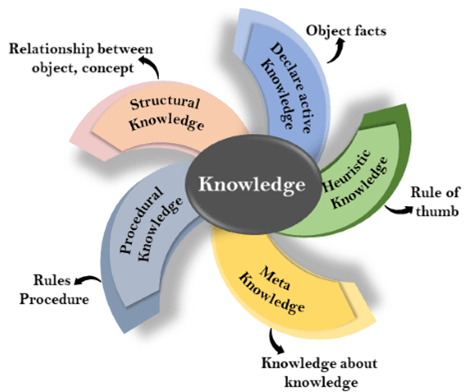
1. 知識表徵的準確性
要讓AI理解並利用知識來解決複雜的現實問題,首先需要將這些內容轉化為數學語言,變成AI可解的數據化路徑。
不過,一個AI系統中需要被表示的知識類型有很多,想要全面且準確地表示出來並不容易。
其中,既有容易被表徵的陳述性知識,如何做某事的程序性知識;也有不易被描述出來的知識,像是基於某個領域的專家經驗所總結的啟發性知識,就未必全是正確的;以及表示概念關係的結構知識,比如分子和分子的相互作用,目前人類了解得還不夠全面。
知識表徵的準確性,將直接影響到機器是否能像人類一樣智能。
2. 知識推理的多樣性
推理能力是人類與其他物種最大的不同,尤其是創造性思維。
而知識計算的核心能力正是推理能力,根據現有的表徵結構產生相對應的新知識,為產業側提供創造性見解。
完全可以想象這樣一個場景:建立一個龐大的知識庫,儲存著人類完成各種任務所需要的知識,AI不再需要對每一個特定場景、特定數據集進行專門訓練,可以像一個真正的聰慧人類一樣,觸類旁通、舉一反三,輕鬆地完成推理分析,應對現實世界中各種各樣的複雜任務。
3. 知識獲取的自動化
建立常識庫並不是件容易的事,也被叫做「AI 的曼哈頓工程」。
尤其是信息爆炸帶來的海量數據,需要機器接管將信息轉化為知識的工作,要提高知識獲取的效率,自動化成為必須啃下的一塊硬骨頭。
使用自動化方法來獲取新知識,能夠加快AI知識系統迭代,實現模型的自動更新,縮短構建行業知識圖譜的時間。
4. 知識應用的高效率
不同行業的知識沉澱、應用、管理方式千差萬別,讓企業自己去搭建一套個性化工具並不現實。
因此,知識計算想要落地行業,還需要一系列標準化工具,提供知識搜索、高性能查詢、可視化分析等功能,提高對知識的挖掘效率。
作為一個新崛起的技術方向,需要有前瞻眼光的平台化科技企業與組織來做好基礎設施建設,並將能力介面向各行各業企開放。
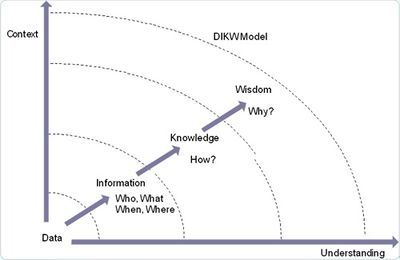
數據和信息描述世界,知識和智慧理解世界。
從這個角度說,AI在DIKW金字塔上的層次越高,能力就越強,距離強人工智慧也就越近。
這條攀爬之路並不好走,卻是AI產業化和產業AI化的必經之路。
最後的最後,當AI登上金字塔尖的那一刻,獲得真正的智慧,屆時我們已經不能確定,AI會不會是地球上最聰明的物體了。或者說,人類還在智慧的最高層嗎?
正如艾略特在詩中所寫的:「我們在哪裡丟失了知識中的智慧?又在哪裡丟失了信息中的知識?」(Where is the wisdom we have lost in knowledge?/ Where is the knowledge we have lost in information?)
曾幾何時,智慧是人類所特有的東西,是人作為萬物之靈長的代表。很多人正在數字時代,越來越少地掌握知識、主動思考,越來越多地沉浸於支離破碎的數據和信息汪洋之中。
或許,當我們見證AI向金字塔尖攀爬的時候,更重要的是,對人類向金字塔底部的滑落保持一點警醒。
#合作媒體#
腦極體,微信公眾號:腦極體。寫讓你腦洞大開且能看懂的人工智慧、流媒體、海外科技
本文原創發佈於人人都是產品經理。未經許可,禁止轉載
題圖來自 Unsplash,基於CC0協議