
編輯導語:近些年CG技術、人工智慧技術等的不斷發展,催生了虛擬人概念的出現。虛擬人到底是什麼呢?本文作者從身體、靈魂、世界、人設等方面對虛擬人進行了分析,一起來看一下吧。

了解虛擬人賽道產品相關信息請看我的前兩篇文章:《虛擬人漫談|開拓:產品篇(上)格局與環境》、《虛擬人漫談|開拓:產品篇(下)產品與商業》。
01 虛擬人,新科技下的創世神話
想象一下,你是一個創世神,擔負著創世的KPI,你要做點什麼?
我想,你大概應該先構思好主角,再扔給主角一個世界。
主角首先是一個擁有大腦軀幹四肢,眼睛鼻子嘴的生物,姑且把這種生物叫做「人」。
但僅僅這樣還不夠,每個人的身上還要加一點點靈魂,有的多一點風趣幽默,有的多一點審慎優雅,各有不同,才會豐富多彩。
最後,再給他們一個世界,賦予天空和大地,賦予植被和海洋,再來點可愛的小動物……這個創世任務的MVP,就差不多算完成了。
在人類的幼年時期,各個文明流域都相對獨立地出現了創世神話,上古中國有盤古開天闢地,女媧摶土造人;《聖經》中有上帝七天創世,並在第六天創造了亞當夏娃的故事……一直以來,人類都對自己的起源充滿了好奇與想象,創世神話,是人類對自身起源浪漫探索的開始。
這種對自身充滿探索和嚮往的慾望一直固化在我們的集體潛意識裡,而在科技日漸發達的今天,我們正逐漸嘗試用科技來擬合一個「人」的誕生過程,這就是「虛擬人」的概念。

「虛擬人」並不是一個常規意義的有血有肉的人,而是一個綜合了多類技術而形成的,生活在數字世界中的「人」。虛擬人概念的催生,也正是得益於近些年來CG技術、人工智慧技術等的不斷發展。虛擬人是一個技術的綜合體,是人類用科技擬合自身的浪漫探索與想象。
02 虛擬人是什麼
虛擬人是什麼呢?人類理解一個事物的時候往往喜歡首先探究它的概念。對於虛擬人這個概念,很多機構試圖給出它的定義,或者是分類,比如有的認為可以分成「虛擬人」、「數字人」、「數字虛擬人」,有的認為可以分為「meta hunman」和「AI being」等等。
我本人沒有那麼權威,但也想給虛擬人下一個定義,這個定義是什麼呢?那就是:當我提起「虛擬人」這個概念的時候,你的腦海里浮現出了什麼?Bingo,那就是虛擬人!
其實,虛擬人本質上是對人的一種模擬,對「人」這個概念的解構,能幫助我們更好地認識虛擬人。如何賦予虛擬人更有價值的生命,也許就要先從對「人」的探索開始。接下來,我們就從一個「人」本身來出發,看看人由哪幾個關鍵的部分組成。搞清楚了這個之後,針對每一個部分,再來聊一聊,虛擬人是如何通過多種多樣的技術來擬合人類的。
03 「身體+靈魂」+「世界+人設」
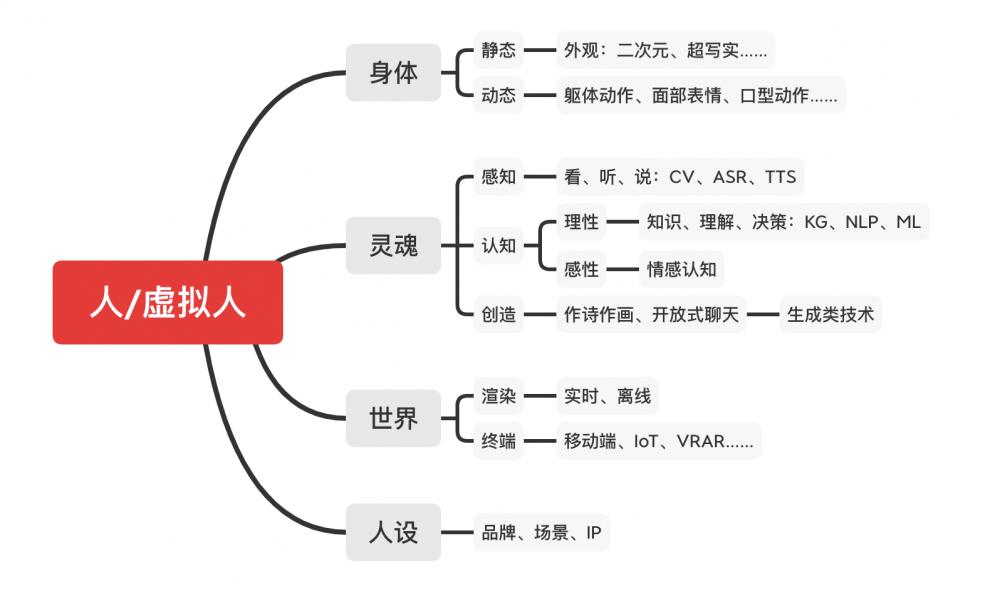
何為人?針對這個問題,我先拋出一個我認知里的公式:
人=「身體+靈魂」+「世界+人設」
身體和靈魂,靈與肉,這是組成生命的唯二兩個部分,我想這個結論應該是大多數人都能認可的。我這裡說的身體可以譯為body,主要是指我們自身上「有形」的那一部分,包括我們的軀幹、四肢、手腳,以及看的見的表情動作等;相對的,靈魂可以譯為soul,這裡主要是指我們身上那些「無形」的部分,例如我們的感知、意識、知識、感情等。
有了身體與靈魂,我們可以說已經得到了一個「人」了,但僅僅這樣還是不夠的。馬克思說過,「人是一切社會關係的總和」。一個人的社會屬性很重要,對於虛擬人來說也是如此。
對於虛擬人的社會屬性,我也把它簡單概括為兩個方面:世界和人設。世界代表外部環境,虛擬人也需要一個生活的空間,一個舞台,這是外界給TA的;人設代表內部環境,虛擬人也需要有社會屬性,需要合適的外貌、技能、性格……這是TA回饋給外界的。
那麼,以上這四個元素是如何作用的,從技術的角度又是如何實現的,且聽我細細道來。
1. 身體
從唯物的角度來看,身體是人必不可少的組成部分。這裡,我把身體這個元素進一步拆成兩個要素,分別是:靜態+動態。
1)靜態
指人的外觀,對於真人而言,外觀有高矮胖瘦、膚色、男女等區別,而對於虛擬人而言,還增加了「畫風」這一維度,虛擬人的外觀可以包括二次元、3D、超寫實,甚至賽博朋克等,目前,虛擬人的外形主要靠美術設計師和3D建模師共同實現。
2)動態
指人的動作,一般來說,人的動態分為三個主要部分:
- 軀體動作
- 面部表情
- 口型動作
這一點對於真人和虛擬人都是比較類似的(虛擬人暫時不涉及動耳朵、動頭皮這種高級藝能)。虛擬人的動態主要依靠驅動技術來實現,目前驅動技術主要有真人驅動和AI驅動兩種流派。
2. 靈魂
就像電影《心靈奇旅》里演的那樣,靈魂也是一個人的重要組成部分。對於虛擬人來說,靈魂主要是通過AI技術來打造的。這裡,我把靈魂也分成了幾個要素:
1)感知
感知是人最生物性的層面,主要是和我們的五感有關,具體來說就是看、聽、說三個部分,分別由眼睛、耳朵、嘴來負責,結合到AI能力,就是CV、ASR、TTS。
2)認知
認知是在感知的基礎上進一步形成的思考能力,這裡我把認知能力進一步分成兩個方面,分別是理性的認知能力和感性的認知能力,其中,理性的認知還可進一步分為知識儲備、理解、決策三個層級的能力,對應於AI中的KG、NLP、ML;感性的認知主要指的是利用AI構建的情感識別功能。
3)創造
就像我們小學的時候會先學習漢字,學習造句,再學習寫作文一樣,創造是更高一級的智力活動,只有在進行過大量的學習之後,才能進行有效的創造,人如此,虛擬人亦如此,虛擬人的創造主要依賴於生成類的AI演算法來進行輸出。
3. 世界
對於一個人,我們要給他一個世界,一個舞台,這個人才算有了一個全面展示自己的空間,虛擬人亦如此,這個世界就是虛擬人生活的空間。關於世界,這裡我也(強行)分成兩個要素:
1)渲染
渲染就是讓這個虛擬的「人」呈現在我們面前,渲染技術分為離線渲染、實時渲染等,渲染技術的選型會直接影響虛擬人的呈現效果,你看到的是4k還是1080p與它有直接關係,渲染技術很大程度上決定了虛擬人演出的舞台效果。
2)終端
虛擬人沒有物質性的實體,目前階段我們必須藉助終端才能看到它,現在可以承載虛擬人終端的設備數量越來越多,移動端、IoT、VRAR等都有大量的空間。在未來,虛擬人技術也有可能真正和實體機器人進行結合,變身成真正幾乎「以假亂真」的智能體。
4. 人設
我們總說明星有人設,其實每個人都有人設。人生在世,誰又能時時刻刻保持自己永遠都是一個耿直的real boy/real girl呢?我們在面對家人、朋友、同事時,甚至會換上不同的人設。對於虛擬人而言,這也是一樣的,而且由於虛擬人現在還比較「笨」,不能像真實的小精靈鬼們一樣多種人設無縫切換,因此,對於每一個虛擬人而言,打造一個專有場景的專有人設至關重要。
人設就是面向社會和公眾在特定場景下所表現出來的品牌、IP等,一個好的人設,不僅僅需要合適的外形風格、肢體動作,也需要合適的知識儲備、談吐風格、甚至創作風格。人設不是一個技術類的概念,它更偏向於產品和運營方面。
運營好一個IP類虛擬人,和經紀公司運營一個明星的道理是一樣的,甚至有更大的難度,而擁有好的人設IP運營sense的企業在虛擬人賽道甚至元宇宙時代里脫穎而出的概率也是極大的。
以上,就解釋清楚了我自己對於虛擬人定義的邏輯框架:
人=「身體+靈魂」+「世界+人設」
其邏輯腦圖如下圖所示
接下來,我將依照這個邏輯分別簡單展開陳述一下相關的技術向內容。
04 身體
「身體」又被我進一步分成了兩個要素:靜態與動態。靜態就是我們的外殼,包括頭、軀幹、四肢等,動態就是身體的動作,面部的表情,說話時的嘴形等。
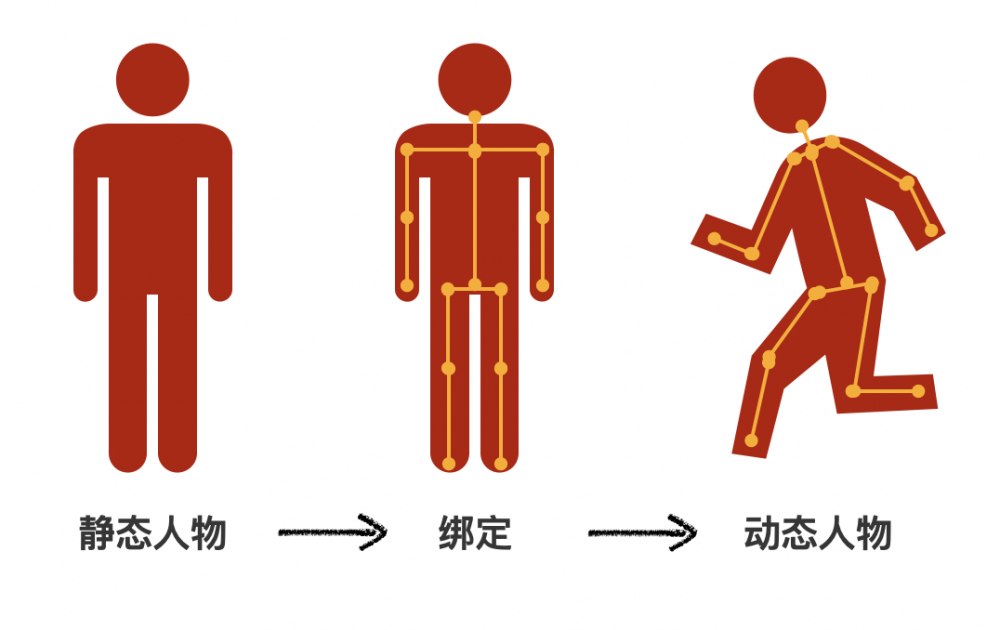
對於一個真實的人來說,這一切都是來的自然而美妙,我們的身體由母親孕育而來,體內有無數的神經細胞控制著每一塊肌肉的運動,身體和靈魂是一個有機的整體。但對於虛擬人而言,這一切就沒那麼自然了,全要倚賴人類的設計。其中,靜態外形的誕生主要依賴於各種建模技術;動態的產生則要依賴各類驅動技術。
對於虛擬人而言,想讓靜態和動態聯動起來,二者之間必須的一個橋樑就是綁定,通過對身體各個骨點的綁定,來達到控制各個身體部分動起來的目的,如下圖所示:
1. 靜態
靜態外形的誕生主要依賴於各種建模技術,目前的建模方式主要有以下幾種:
- 3D軟體建模
- 儀器採集建模
- 自動化建模
建模方式一:3D軟體建模
指通過3D建模軟體來人工塑造出3D的模型,該方式人工製作周期較長,但效果可控,是目前應用最廣泛的建模手段。
常用的3D建模軟體有很多,主要有以下幾類:
- 傳統3D建模:3Dmax、Maya、blender等
- 雕刻軟體:zbrush、blender等
- 程序化建模:houdini等
其中,傳統3D軟體主要負責製作低模,雕刻軟體可以輔助製作高模,限於篇幅原因,這裡不做過多展開,總之,低模的特點是面數少,視覺效果一般,但所佔計算資源少,運行速度快;高模則正好相反,面數多,視覺效果好,但佔用資源多,容易卡頓。
下面這塊磚頭很好的解釋了高模和低模的區別(雕刻軟體的「雕刻」二字含義就是精細的雕出坑坑窪窪的細節,使其看上去更真實)。

現代建模流程中一般會使用「烘培」的方法,簡單來說就是底層結構是低模,但是在低模的面上貼上高模的貼圖,類似於「披著羊皮的狼」,達到一種看上去視覺效果很好,運行速度又快的效果。
手工建模有多種工作流程,主要的可以分成傳統模式、次世代模式兩種:
- 傳統模式:大概流程是先作低模,然後直接手工畫貼圖,結構上的材質等信息全靠人手作畫,這種方式只能做出比較卡通的模型,做不出特別精緻的效果。
- 次世代模式:大概流程是先做低模,然後用zbrush等軟體做雕刻使其變成高模,然後再把各個面的貼圖拆分,再烘焙回去,這樣一來,模型結構是低模的,上面的貼圖是逼真的高模渲染出來的,因此看上去既真實,又不卡內存,次世代模式可以做出非常精緻的模型。
3D建模技術涉及到計算機圖形學、3D美術等多方面技術,限於篇幅和水平原因,這裡敘述的比較淺顯,日後如果有更多研究我會再進行更細緻的補充。
開個小差:很多小夥伴應該都聽說過美術生會經常畫人體素描,還會因此產生一些羞羞的聯想,但其實我作為一個超業餘美術愛好者,深知人體真的是很難畫的,其難點主要有三:
- 人體真的很不規則,可以設想,你能見到的大部分物體都是比較規則的,想想你身邊的床、柜子、桌椅板凳……出於工業設計與製造的方便,大多我們用到的物品都是由立方體、圓柱體等基本圖形以及其組合而演變來的,而人體卻是複雜的骨骼外面包裹了複雜的肌肉,既不是全方的也不是全圓的,哪怕是一條簡單的胳膊也包含了微弱的高低起伏,因此是非常難以概括的。
- 人的動態非常豐富,一個人的肢體活動是非常多變的,而多變的肢體活動帶來的是肌肉的拉伸、擠壓和複雜的透視,因此,想做出非常自然的虛擬人姿態難度是很大的,需要對各個肌肉及其聯動的數據權重進行大量的微調,是需要非常豐富的建模及綁定經驗的。
- 人對人的敏感程度非常高,這就好比畫一棵樹,只要我畫了一堆樹葉上去,你可以完全不在乎樹葉畫的是不是和窗外那棵一模一樣,只要能看出來是樹,就可以了;對於人就不是這樣了,世界上有這麼多人,卻很難找到兩個長得一模一樣的人,人對於人臉的敏感程度非常高,稍微不像就能看的明顯,因此對於一些高保真的明星偶像的建模,也需要強大的美術功底才能支撐。
建模方式二:儀器採集建模
相比於手工建模,儀器採集建模是通過儀器掃描的方式來進行建模。該方式成本較高,目前一般用於影視特效製作等領域居多。儀器採集建模技術分為靜態掃描建模和動態光場重建:
- 靜態掃描模型技術是目前的主流,可具體細分為結構光掃描重建與相機陣列掃描重建等。
- 動態光場重建技術是目前重點發展的方向,不僅可以重建人物的幾何模型,還可一次性獲取動態的人物模型數據,並高品質重現不同視角下觀看人體的光影效果,具有高視覺保真度。
許多關於虛擬人的行研報告里都有關於以上兩種技術的詳細介紹,例如國海證券的《數字虛擬人——科技人文的交點,賦能產業的起點》中,「圖表:主要建模技術概況」就概括的很好,有興趣的讀者可以找來看看。
建模方式三:自動化建模
自動化建模主要包含以下一些方式:
- 圖像採集建模:通過採集照片來還原人臉 3D 結構
- AI建模:利用AI演算法直接生成人臉、身體等的建模方式
自動化建模技術目前還不算特別成熟,建模結果到直接商用還有一段距離,不過,該類技術會大大降低建模的人力成本和時間成本。目前已經出現了一些支持虛擬人創建的工具化平台,如英偉達的 Omniverse Avatar、Epic Unreal的 MetaHuman Creator 等。尤其是2022年6月最新發布的Unreal的MetaHuman Creator ,其效果令人驚艷。
這些平台的建模精度雖不足以建立超高質量的模型,但能夠大幅降低虛擬人建模的成本,讓普通人也能快速擁有屬於自己的虛擬形象。隨著技術的發展,自動化建模的效果還會變得越來越好。在未來,這種方式有可能直接實現虛擬人生產流程的自動化,和元宇宙入口、虛擬分身、千人千面等概念聯繫起來,擁有巨大的想象力。
2. 綁定
綁定技術是動態與靜態聯動的橋樑,簡單來說就是給做好的虛擬小人在關鍵位置打上點,方便後續通過驅動關鍵點來驅動小人做出各種表情與姿態。關鍵點的位置遍布全身,例如軀幹上,手肘、手腕、膝蓋、腳踝等關節就是關鍵點;面部的眼皮、嘴角、眉頭等關鍵位置也要打上關鍵點,讓虛擬小人「眉飛色舞」。
筆者自己曾學過簡單的Maya骨骼綁定,簡單來說,軀體部分的綁定的流程如下:
- 創建骨骼(就是做個火柴人出來)
- IK等方式添加骨骼的聯動(例如腳踝抬起時膝蓋也會自然彎曲)
- 為骨骼蒙皮(就是把虛擬人的「血肉」和「骨骼」的關鍵點一一對應起來)
- 調整權重(讓虛擬人在運動時肌肉的形變更加自然)
面部的綁定流程和軀體整體而言差不多,只是面部需要人做很多表情,做表情的時候諸如眼皮、嘴形、眉頭、蘋果肌等都會進行聯動,因此面部綁定所需要的關鍵點更多更複雜。
隨著技術的發展,工業流程的演進,綁定技術也在向著更便捷、更高效、更智能、邊際成本更低的方向發展,關於這一點可以參看的國海證券《數字虛擬人——科技人文的交點,賦能產業的起點》中的「圖表:綁定環節的技術革新」。
3. 動態
完成以上兩步之後,我們就可以通過驅動的方式讓虛擬人動起來。整體而言,虛擬人可以分為交互型、非交互型兩種。
非交互型主要通過設置預製動作來讓人物動起來,類似於動畫片的原理,不能實現實時互動。
交互型虛擬人是我們的重點。交互型虛擬人需要靠驅動技術來驅動動作、表情、嘴形,這樣,虛擬人才能做到根據外界刺激進行反饋的效果。交互型數字人的驅動可以分為傳統驅動方法和智能驅動方法。
1)傳統驅動方法
可以分成光學動作捕捉、慣性動作捕捉、Track 設備+IK 演算法的動作捕捉等方法,現階段,光學式和慣性式動作捕捉佔據主導地位。傳統驅動方法一般需要」真人+動捕設備」來進行驅動,這個後台的真人又稱為「中之人」
2)智能驅動方法
智能驅動是指通過AI技術,例如CV、ASR、TTS等來對虛擬人進行驅動,該方式造價成本低,可以無限拓展,在未來有很大的想象空間。不過現階段AI技術有限,一般需要結合合適的場景,通過較多垂直領域的訓練才能達到商業可用的效果。
關於這一部分,我同樣參考了國海證券《數字虛擬人——科技人文的交點,賦能產業的起點》中的「圖表:主要捕捉技術特性對比」和「圖表:主要驅動技術概況」。我覺得這份材料的很多總結簡潔到位,是一份非常不錯的參考材料。
05 靈魂
其實用「靈魂」這個詞只是為了表達「身體與靈魂」這一概念的方便,其實我更想表達的是類似於「頭腦、意識」這樣的一個抽象的概念,與身體的「物質性」相對應,它屬於人的「非物質」那一部分,我姑且把它稱為「靈魂」。關於「靈魂」我想分為3個層面來介紹,分別是感知、認知和創造。虛擬人的「靈魂」主要需要依賴各種AI技術來進行賦能。
1. 感知
感知是人最生物性的層面,主要是和我們的五感有關,具體來說就是看、聽、說三個部分;目前,直接的知覺、嗅覺等技術還不成熟,也許未來的腦機介面、體感設備等技術會在這些方面有所突破。
虛擬人的感知技術主要依賴於人工智慧,在感知層面,人工智慧技術當下整體而言是成熟的,不成熟的部分短時間內也難有重大突破,因此一般需要結合具體場景,通過合理的產品設計和精細化運營等方式來達到可用的程度。
看:計算機視覺CV
計算機視覺技術可以幫助虛擬人「看」到物體,並作出一定程度的簡單分析。計算機視覺技術主要依靠深度學習中的CNN網路,一般的技術應用均為CNN的變種。CV技術主要有以下幾類應用。
1)分類
給定一張輸入圖像,圖像分類任務旨在判斷該圖像所屬類別,例如,檢測出一張照片中的主角是貓還是狗等,常用的分類網路包括AlexNet、VGG-16/VGG-19、ResNet等
2)檢測
在圖像分類的基礎上,給出圖像中的目標包圍盒,常用的目標檢測演算法包括:
- 基於候選區域的目標檢測演算法,如R-CNN、Fast R-CNN、Faster R-CNN等
- 基於直接回歸的目標檢測演算法:如YOLO、SSD等
3)分割
可以進一步分為語義分割、實例分割,均可理解為更加精細的檢測任務,常用演算法包括Mask R-CNN等。
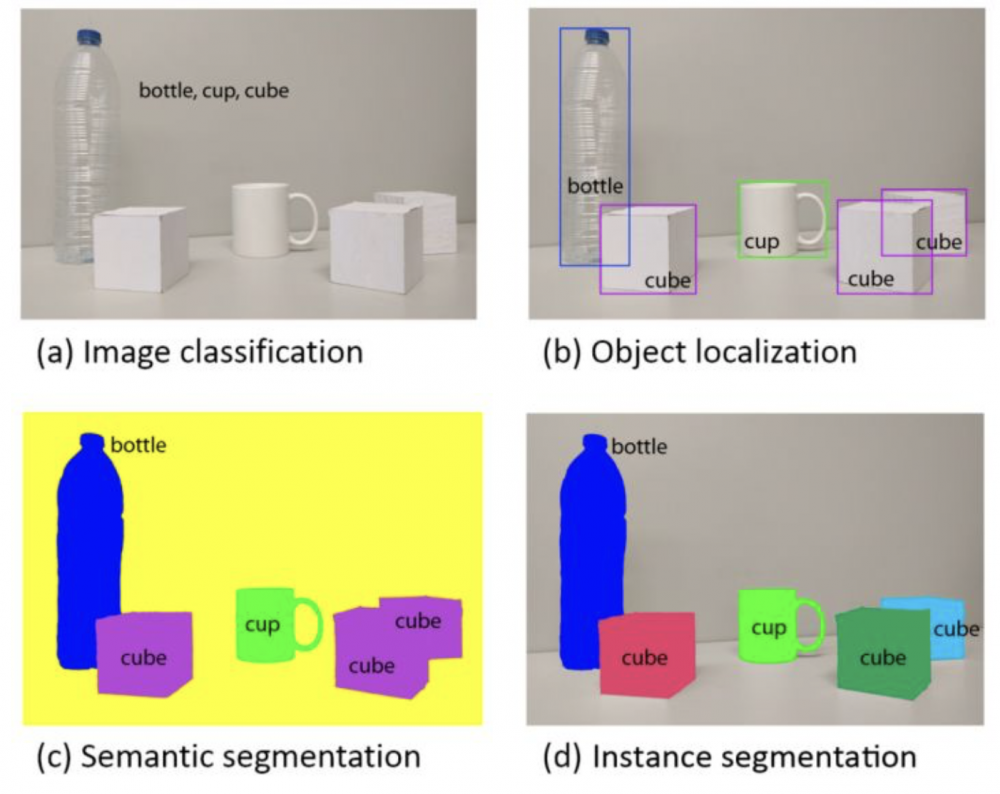
下圖非常形象地表示出了CV的幾種關鍵任務,分別是:
- 分類
- 檢測
- 語義分割
- 實例分割
CV類技術有非常廣泛的應用,例如人臉識別、姿態識別、障礙物識別等,這些具體的應用技術均可以和虛擬人賽道進一步結合來滿足虛擬人的不同應用場景。
聽:語音識別ASR
將聽到的聲音轉化成語言的技術,主要分為聲音接收和聲音識別兩個部分。
聲音接受部分主要依賴於硬體、環境及聲源,一般來說,較高級的聲音接收設備、噪音較小的環境,發音標準且音量適中的聲源均會提升聲音接收的質量。
聲音識別部分主要依賴於機器學習及其中的深度學習等AI技術,主要可分為傳統方法和端到端方法:
- 傳統方法:需要先提取聲音信息特徵,例如MFCC、LPCC等,這裡主要涉及信號處理相關知識;提取特徵后再採用HMM、語言模型等綜合得出識別結果。
- 端到端方式:主要依託於深度學習技術,由於語音本身是具有時序性的(倒放的語音很難聽懂),因此語音識別主要依託以RNN為基礎的時序類深度學習模型,例如其衍生出的LSTM、GRU等,來完成語音到文字的轉化工作。
說:語音合成TTS
把文字轉化成語音播放出來的技術就是TTS技術,能形成自然、流暢、動聽的聲音是TTS技術所追求的目標。
從技術的角度來看,TTS系統主要分為前端系統和後端系統:
前端系統負責對文字進行分析,並形成一份「發音指南」,裡面包括每個字的讀音音素、連讀、重音、停頓、多音字讀法等,這份「發音指南」就像一個發音「說明書」,會傳給後端。
後端系統按照前端生成的「發音說明書」,負責把聲音合成出來,目前主流的後端合成技術有兩大類,分別是「拼接法」和「參數法」。
- 拼接法:先通過真人錄製聲音,再根據「說明書」把需要的聲音片段拼合起來,這種方法優點是聲音本身自然動聽,缺點是人力成本高,且流暢度容易出現問題。
- 參數法:用聲音信號的參數,如基頻、頻譜等來表示聲音,將「聲音說明書」中每一個音素的「參數」找出來,合成對應的聲音;參數法的優點是成本低,缺點是機械感比較明顯,不夠自然,不過該方法會隨著技術發展效果越來越好,應用範圍也會越來越廣;目前比較主流的參數法一般是使用端到端的方法,例如Tacotron2、WaveNet等。
2. 認知
認知是在感知的基礎上進一步形成的思考能力,這裡我把認知能力進一步分成兩個方面,分別是理性的認知能力和感性的情感識別能力。
理性認知能力
1)知識:知識圖譜KG
知識主要依賴於知識圖譜技術。知識圖譜是給知識形成的一個以三元組
實體<—>關係<—>實體
為核心的邏輯圖,例如以中國城市為主題的邏輯圖,就是下列形態:
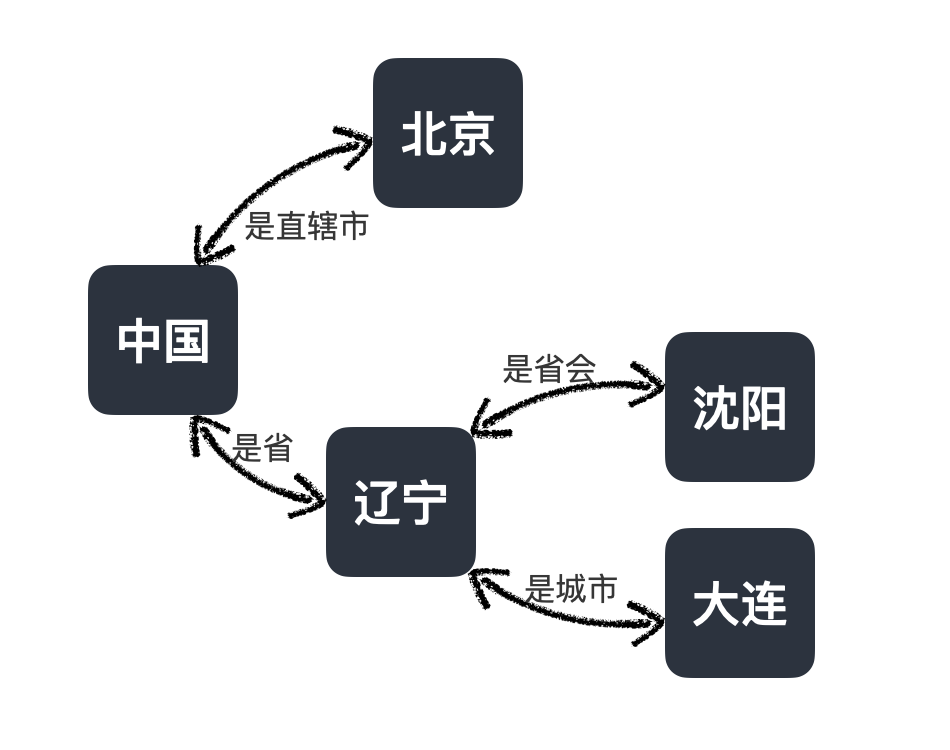
其中,「中國」、「北京」、「遼寧」、「瀋陽」等都是實體,「是直轄市」、「是省」、「是省會」等就是關係。
知識圖譜可以在任意知識領域運用,例如金融業有銀行理財知識圖譜、保險知識圖譜等;農業領域有動植物知識圖譜、農作物知識圖譜等;一個好的知識圖譜就是一個邏輯清晰的知識寶庫。
知識圖譜可以以圖資料庫、三元組資料庫等形式進行存儲。如果把知識圖譜「喂」給一個虛擬人,該虛擬人就有了這個方面的豐富知識。例如,銀行業務導引虛擬人就需要非常豐富的銀行業務知識,文旅導遊虛擬人就需要對導遊相關知識非常了解……
知識圖譜能快速賦予虛擬人以某一方面的專業知識,堪比《西遊記》中的孫悟空吃掉一本書立刻就能掌握書中內容了。知識圖譜的完善對於虛擬人的應用意義非凡,而知識圖譜本身技術難度不大,其完善主要的門檻在於對於垂直細分行業的深度理解。
2)理解:NLP
通過感知,虛擬人可以獲得外界的信息。通過CV「看到」的信息,通過ASR「聽到」的信息,都可以轉化成語言文字的形態。但僅有感知還是不夠的,虛擬人不僅要能獲取信息,還需要理解這些信息所代表的真正意圖,明白感知到的信息的含義,才能做出下一步的動作。
NLP技術的全稱是自然語言處理技術,重點就是理解語義信息,主要包括詞法分析、句法分析、語義分析、情感分析等幾個部分。通過NLP技術,可以做以下事情:
- 對一句話進行分詞(主要針對中文等語言,英文就不用了)
- 分析出每個詞的詞性,判斷是名詞還是動詞,是形容詞還是副詞等
- 分析出句子的語法結構,例如主謂賓等
- 分析出各個部分的施事受事關係,例如「我打你」,「我」是施事,「你」是受事
- 通過語氣詞、「喜歡」、「討厭」等關鍵詞分析出句子的情感傾向
通過以上種種環節,虛擬人便可以通過NLP技術來理解感知到的信息的含義,識別出信息的意圖,便於後續做出進一步的反饋等交互動作。
3)決策:數據智能ML
決策能力是人的一項重要素質,對於虛擬人來說,也可以通過AI的方式提升決策能力,而這一能力的提升主要依賴的就是各種數據智能模型。
簡單來說,數據智能就是通過搜集某一問題的大量歷史數據,再通過機器學習的某個演算法擬合出該問題的函數模型,並依據函數模型對未來做出預測與決策。例如,可以通過某一產品的歷史銷量分析出該產品未來的銷量走勢;可以根據球隊的歷史勝負情況來預測未來某一場球賽的結果等,宛如那年夏天的章魚保羅。
常用的可以用於決策建模的機器學習演算法非常多,從有無標籤可以分為有監督、無監督、半監督;從任務類型可以分為分類、回歸、聚類、時序預測等。經典的機器學習演算法很多,例如決策樹、支持向量機、XGBoost等等,篇幅原因不做具體展開,感興趣的讀者可以看一看周志華老師的西瓜書。
對於數據智能任務而言,模型其實並不難,現階段真正難的是是否有足夠多的有價值的數據。互聯網、金融等企業相對而言有效數據的收集意識較強,但很多傳統企業,收集數據的意識還較弱,目前也正在數字化轉型當中。隨著數字化轉型的進程,虛擬人也會有越來越多的應用。
情感識別能力
人不僅需要理性,也需要感性。親情、友情、愛情,人與人之間的交往往往是感性大於理性的。對於虛擬人而言,除了理性方面的知識、理解、決策等能力,對於情感的把握也是應該具備的品質。能夠進行情感識別、情感反饋的虛擬人,在目前還是藍海的陪伴型虛擬人賽道有著巨大的用戶價值和商業價值。
情感識別是一項綜合的能力,例如,通過CV技術,虛擬人可以分辨人的表情是開心還是難過;通過ASR技術,虛擬人可以通過聲紋來分析說話人的說話語氣是高興還是壓抑,甚至是憤怒;通過NLP技術,虛擬人可以分析說話人說話的內容中,是否含有強烈的表達態度的語氣詞,例如「喜歡/不喜歡」、「垃圾」、「太贊了」……
心理學家羅伯特·普拉切克提出了情緒輪,內含8種基本情緒,可以作為情緒識別標籤設計的依據。
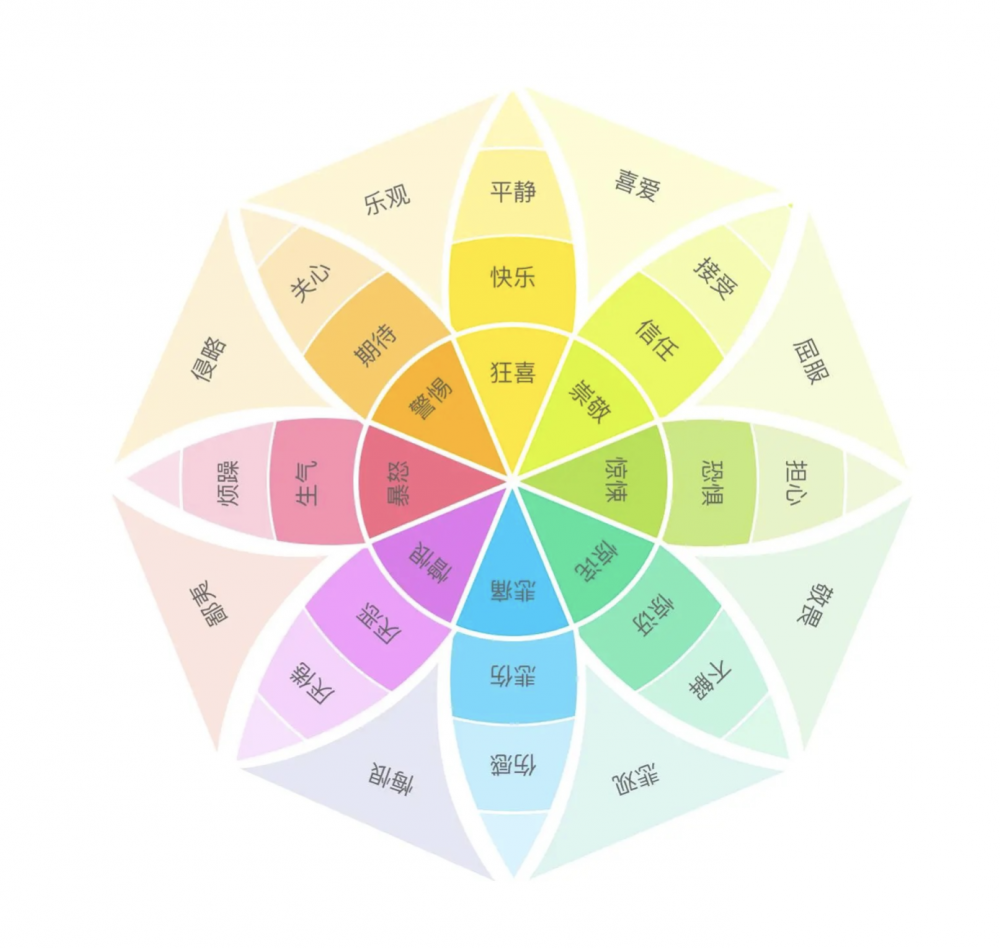
情感識別的能力目前已經在輿情控制、課堂教學等領域得到了一定的應用,但整體而言現階段還不夠成熟,還有巨大的探索空間。
3. 創造
就像我們小學的時候會先學習漢字,學習造句,再學習寫作文一樣,創造是更高一級的智力活動。只有在進行過大量的學習之後,才能進行有效的創造,人如此,虛擬人亦如此。
目前,「創造」主要是用在虛擬人的創作領域,例如AI作畫、作詩、寫新聞稿、開放式聊天等等,主要依賴的是以GAN為基礎的生成式模型。
整體而言,創造類技術目前成熟度不高,僅在一些規範性比較強的領域如新聞稿等有一些成功案例,更多的應用還集中在概念展示階段,距離真正大規模商用,還有一段距離。距離產生美,這也給虛擬人未來的潛力提供了巨大的想象空間。
06 世界與人設
之所以分成「身體+靈魂」、「世界+人設」,是因為前兩個代表個體,后兩個代表外界。而在後兩個元素中,「世界」是外面給我們的,是由外而內的,人設是我們給外面的,是由內而外的,美妙嗎?非常美妙。
1. 世界
世界,就是虛擬人生活的周圍環境。在有了一個虛擬人之後,我們還需要給它一個載體,一個舞台,讓虛擬人走到台前來發揮它的價值。構建虛擬人世界的技術,我想談兩個點,分別是渲染和終端。
1)渲染
渲染,就是把做好的模型呈現在屏幕上的過程,或者說需要通過數學計算的方式,把做好的模型變成計算機屏幕上一個個像素點的顯示RGB值,來完成實際顯示的過程。渲染主要涉及到的技術是計算機圖形學,這一過程需要大量的關於頂點位置、顏色、光照等的計算,也會消耗大量的計算資源。
渲染主要可以分為離線渲染和實時渲染,其中,離線渲染主要用在電影、廣告等可以提前做好無需交互的場景里,允許花費較長時間,因此效果很好,但成本也很高;實時渲染主要用在遊戲、直播等需要實時互動的場景里,對時間比較敏感,因此效果略弱於離線渲染。
Unity和Unreal以往都是用來製作遊戲的遊戲引擎,二者都是實時渲染的利器。雖說比不上離線渲染的效果,但二者的製作水平也在不斷升級,目前新出的Unreal5,其能夠達到的渲染效果已經非常優質,實時渲染的效果正在一步步向離線渲染逼近。

(註:本圖來自國海證券《數字虛擬人——科技人文的交點,賦能產業的起點》)
另外,近些年來發展的PBR技術對於虛擬人的發展也至關重要。PBR 是基於真實物理世界的成像規律模擬的一類渲染技術的集合,它使得渲染效果突破了塑料感。該項技術使虛擬數字人皮膚紋理變得真實,進而有助於突破恐怖谷效應。常見的幾款 3D 引擎,如 UE4,Unity 3D 5等,均有了各自的 PBR 實現。
實時渲染技術的發展可以讓虛擬人在交互的環境下提升用戶體驗,對於VR、AR等賽道的普及與發展有極大的助力。
2)終端
當前,虛擬人沒有實體,是需要依託屏幕來顯示的,因此虛擬人需要生活在終端里,虛擬人如果有實體,那就不叫虛擬人,叫機器人了。其實,現在已經有材料等領域的科學家在研究非常類似於人表皮組織的材料,以期待能做出幾乎以假亂真的「人形機器人」,該項技術近期也取得了一定的突破性成果。2022年6月,日本東京大學宣布,世界上首次成功開發出人工培養的「活」皮膚覆蓋的手指型機器人。但該類技術距離真正成熟還有很遙遠的距離,而且也面臨著社會倫理等方面的巨大挑戰。
總的來說,最近一段時間,虛擬人還是要深度依賴電子終端的。隨著科技的發展,虛擬人能夠活躍的終端種類也越來越豐富,我簡單總結了一些我能想到的各類終端,分類並不嚴謹,只是一個大致的羅列:
- 常規終端:手機端、PC端、電視大屏端
- IoT:智能家居、智能座艙等終端
- 產業終端:銀行導覽、商場導購等
- 新終端:VR、AR、裸眼3D全息等
2. 人設
最後,再來聊一聊人設。
和上面的內容相比,人設是一個非技術的概念,按說不應該放在「技術篇」來講。但是它偏巧又很重要。我們每個人都有一個最本真的「我」和一個社會的「我」,我們面對不同的人會帶上不同的面具,這一點對於虛擬人來說是一樣的。在技術整體水平基本無法拉開差距的時候,對於一個虛擬人產品而言,更重要的就是是否有一個好的人設。
不同場景、不同設定的虛擬人,其人設是完全不同的,這給產品、運營、技術都帶來了很大的挑戰。
好的虛擬人一定是一個好產品。一個好的產品,有三個要素是必不可少的,分別是敲門磚,護城河,生命線。敲門磚決定門檻,護城河決定優勢,生命線決定盈利。對於虛擬人而言,這三個概念可以這樣理解:
1)敲門磚
敲門磚就是好的人設。虛擬人對於人設的塑造非常重要,如果是一個虛擬偶像,那就需要好的IP、靚麗的外形、活潑的肢體語言,甚至是唱跳、創作等能力;而如果是一個銀行的虛擬員工,TA就應該像萬千打工人一樣,簡約、專業,可靠……總之,是否有一個和場景搭配的外形設計,是否有足夠切合的性格設計,是否能夠依託於一個IP或者品牌,都對虛擬人的後續運營工作至關重要。
2)護城河
優秀的人設,要結合紮實的產品設計和優質的技術實現才有可能達到。不同的人設,其產品的細節設計也是不同的:一個「小女孩」的人設說話一般是俏皮的,一個職員的人設說話一般是專業親切的,這對於產品話術的設計提出了考驗。
從身體外形的角度,虛擬人可以分為二次元、類人、超寫實、未來科幻等不同風格;從人格靈魂上來講,一個銀行引導型虛擬人需要具備豐富的金融行業知識、一個虛擬偶像需要具備唱歌跳舞,甚至是歌曲創作等能力;一個陪伴老人的虛擬人,可能需要豐富的醫療、保健方面知識和對情感的感知與回饋……
人設的打造既要滿足產品的需求,又要兼顧到技術的邊界……可以說,一個成功的虛擬人IP的打造,是非常不易的。
3)生命線
對於任何一個偶像類的強人設型虛擬人,其二創能力非常重要,二創能力可以讓用戶自發參與其中,形成優質的生態圈,同時也對後續的商業化變現有巨大增益;好的二創離不開運營的引導支持,這對於虛擬人來說也至關重要,可以說,二創能力就是虛擬人產品的生命線,決定了虛擬人產品是石沉大海還是強勢出圈,是否能可持續發展。
關於人設,很多人認為虛擬人的一個優勢就是不會翻車,畢竟近期劣跡藝人太多,很多公司都因為劣跡藝人受到了影響,虛擬人似乎是一個零差評零緋聞的不錯選項。但是其實,對於虛擬人來說,運營翻車的例子也比比皆是,這也對虛擬人的運營人員提出了巨大考驗。
07 趨勢&邊界
虛擬人賽道是一個技術的綜合體,任何一項技術的不完善、不成熟,都制約著虛擬人的「類人」程度。總的來說,虛擬人有三條技術路徑:
- 純人工
- 人工+AI
- 純AI
純人工的方式成本過高,純AI的方式技術暫不支持,目前基本採用的是人工+AI的方式,但隨著科技的進步,這一流程中的AI部分佔比會越來越多,虛擬人整體的製作流程也會成本更低、時間更短。
對於虛擬人賽道的發展,我們當下要做的事情是:
- 明確技術邊界,並知道不同環節不同技術下的效果、成本和收益
- 找到合適的場景,通過場景本身的制約、細分領域的打磨來完成應用
- 積極擁抱技術創新
邊界代表當下,趨勢代表未來,我在這裡想淺盤一下主要的技術,並對未來進行一些分析。
1. 邊界與當下
1)傳統方法仍有局限
建模(maya、3Dmax等)、驅動(中之人動捕)、渲染(Unity、Unreal等)方面,已有的非AI類的工具、技術均已較為成熟,但依舊存在著一些問題,例如成本較高、製作周期長、實時渲染效果有限且對設備要求高、過於依賴中之人等。
AI等智能化、自動化等技術的發展正在改變以上領域的流程,未來隨著智能化和自動化的發展,建模、驅動、渲染等工作會朝著成本更低、時間更短、門檻更低、效果更好的方向發展。成本的下探至關重要,成本及門檻下探到一定程度,虛擬人的應用場景才會由B端過渡到C端。
2)AI能力有待提高
AI能夠賦予虛擬人以大腦,AI技術水平的發展直接決定了這個虛擬人是否「弱智」。目前,AI能力的成熟度尚不平均,感知類技術如CV、ASR、TTS等技術已經能夠做到較好的水平,一些AI公司如科大訊飛等也均有相關能力的提供,成熟度較高;而認知能力需要深度的業務知識加成和大量的訓練數據支撐;情感類能力、創作類技能目前尚不成熟,距離大規模商業落地還有一段距離,目前需要依賴精細化的產品設計和運營。
3)其他需要關注的點
我們需要關注的點不僅僅是AI、CG等高度相關的技術,對於周邊的技術例如基礎設施建設、VRAR技術、晶元及算力、邊緣計算能力等的發展,也需要高度重視;同時,偏產品和運營維度來說,對於IP設計、人物設計、二創運營等能力,也需要引起足夠重視。
2. 趨勢與未來
未來虛擬人相關技術的發展將會有幾個大的趨勢:
- 視覺效果更加美觀、流暢、炫酷,這依賴於計算機圖形學、硬體計算能力、顯示設備、建模及渲染工具等的發展。
- AI等智能化技術發展,賦予虛擬人越來越聰明、人性化的大腦,越來越能夠像一個真實的人一樣和人類交流,去體察、決策、陪伴。其中,AI要向兩個方向重點發展,一是具體行業的know-how積累,二是情感型陪伴能力的提升。
- 工作流朝智能化、自動化方向發展,流程縮短、成本降低,若能端到端的生成可用的虛擬人,將為虛擬人的低門檻大批量製作提供可能。
- 隨著VR、AR、IoT等賽道的發展,虛擬人可以活躍在越來越多的終端上,隨之帶來的就是更多的應用場景和能力挑戰。
- 當成本與門檻足夠低時,就有了人均一個甚至人均多個虛擬人的可能。在元宇宙中,虛擬人可以作為NPC、也可以做真人的第二分身,之後無論是結合千人千面、還是結合NFT等概念,都有了無限的想象空間。
- 未來有可能出現真正的類人機器人形態的人工智慧體,屆時虛擬人將不僅能夠生活在屏幕中,還會有一個實實在在的軀體,但就像克隆技術一樣,這樣的技術雖然能夠代表AI、材料、醫療等諸多學科的科技前沿,但是否符合倫理道德,是否能夠商用,將是一個大大的問號。
在網上,看到了百度李士岩的一段話,很有趣。他認為:數字人是基於計算機平台的交互載體,將呈現段落式發展。
當下所處的平面計算時代,主要以服務型與表演型數字人應用為主,下一個階段是更大的時代,暫時定義為空間計算時代。空間計算時代計算平台呈現的信息不再是平面的,而是實時三維的,屆時核心用戶的行為大概會有社交、獲取商品、信息消費、獲得服務四類,那麼能夠提供個性化交互、能提供情緒價值和內容價值的虛擬分身是必選項,能夠提供人文情感關懷、又能保證效率的服務型數字人則是另一種應用形態。在未來的空間計算時代,一定會產生比現在平面計算時代更大的市場。
08 結語
一不小心就廢話了很多內容,其實之所以想寫這個主題,原因就是我對虛擬人這個賽道很感興趣。而之所以對虛擬人賽道感興趣,主要是以下幾個原因:
一是從專業的角度來講,我過去一直是工作在AI賽道的,人工智慧的本質是對智能體的模擬,虛擬人技術是對人工智慧技術的綜合應用,也是人工智慧體的初級階段,這讓我對TA產生了極大的好奇,很想一探窺之;
二是出於個人的一點私心,本人雖是理科生,但對人文科學與藝術領域一直非常感興趣;虛擬人賽道和許多科技類賽道不同,更像是科技與人文的交點,在科技發展的同時也充斥了關於藝術、文化、倫理等的討論,讓我心嚮往之;
三是一點無厘頭的想象,我從小就是一個幻想能力極強的小孩,被二次元深深吸引,我小的時候很喜歡看《數碼寶貝》這類動畫片,倒是挺希望有一天能和這些電視里的英雄說說話的。就當下而言,試問如果熊大熊二喜羊羊能開口說話,和孩子來一番互動教學,是不是也美滋滋的?
出於以上一些原因,我盡個人的綿薄之力對虛擬人進行了一個調研,並且想把調研的內容進行梳理,希望能給讀者帶來一點點收穫。
對於虛擬人這個賽道,我自己也是一個初學者,目前尚不是行業內的工作者,以上內容及觀點主要是通過自學以及基於網路材料的調研形成的。水平非常非常有限,很希望各位業內人士能夠指出我的錯誤和不足,我都會悉心聽取。
十分感謝大家。
參考材料:
- 國海證券《數字虛擬人——科技人文的交點,賦能產業的起點》
- 頭豹研究院《2022年中國虛擬人產業發展白皮書》
- 天風證券《虛擬數字人:元宇宙的主角破圈而來》
- 華麗智庫《全球時尚虛擬人物研究報告》
- 中銀證券《虛擬人行業深度研究》
- 中國傳媒大學《中國虛擬數字人 影響力指數報告》2021年度
- 艾媒諮詢的《2022年中國虛擬人行業發展研究報告》
- 頭豹研究院《2022年AI驅動虛擬人行業概覽》
- 量子位《虛擬數字人 深度產業報告》
- 安信證券《元宇宙之中國優勢:虛擬數字人,分發與流通環節的新戰場 》
- 安信證券《虛擬數字人的長短期展望:IP 與賦能》
- 達摩院《阿里小蜜數字人互動決策的探索與落地》
PS:部分資料源自網路,目的是為了更好的說明所講的問題,如有侵權可以聯繫我進行刪除,不勝感激。