
人們從信息的狩獵者逐漸變成獵物,難怪會被信息流控制自己的情緒。
最近,很多企業都在談演算法的價值觀。在烏鎮互聯網大會上,張朝陽談到了這個話題,在之前今日頭條舉辦的AI大會上,哈佛教授Cyrus Hodes也提到人工智慧應該承擔更多的社會責任。
在以前看到這種論調,我總想為企業喊冤。技術鑽研、產品開發、組織經營已經很費力了,企業創造價值、提供就業就已經足夠負責了。還要為演算法技術這種來源於用戶數據的東西塑造價值觀?不過在了解過Facebook一個有頗多爭議的實驗后,我開始逐漸改變了這種想法。
在2013年,Facebook聯合康奈爾大學、UC舊金山分校的研究員在2013年於美國國家科學院院刊發表了一篇名為「社交網路中大規模情緒擴散的實驗證據」的論文。實驗的主要內容是,更改用戶信息流中的情緒,看看用戶會有怎樣的反饋。事實證明,在用戶信息流中灌輸「正能量」的信息,用戶也會給出正面的反饋,反之則是給出負面的反饋。
由於這則實驗是在用戶不知情的情況下進行的,「實驗」人數涉及到了將近七十萬人。互聯網上對這則實驗進行了強烈的抨擊,認為Facebook的行為極大的違反了人倫道德。
其實我們都知道,真正讓人們感到恐懼的,是Facebook可以通過信息流輕易操縱人們情緒這件事。
從獵手到獵物,弱者才會被「操縱」
回溯到互聯網的「上古時代」,人們尋找信息的方式是非常簡單的。例如搜狐的黃頁形式,整個互聯網上的信息寥寥無幾,以至於可以用分類排列的形式展現出來。當時的人們要知道自己要找的網站屬於那一類,才能在黃頁互聯網上盡情衝浪。
此時人們對獲取信息的把控力可以達到90%。在昂貴的撥號網路之外,還有大量的電視、廣播、紙質媒體構成人們對世界的認知。
隨著信息的爆髮式增長,一本黃頁已經遠遠不足夠。到了谷歌、百度的搜索引擎時代,關鍵詞成為了尋找信息的利器。這時的人們已經可以帶著問題來尋找信息,SEO、SEM等等廣告形式也讓企業開始有權力去「控制」用戶看到那些信息。
同時,廉價的寬頻資費和更豐富的信息增加了互聯網的權重,讓其在人類認知來源構成中的地位更高。換句話說,人類認識世界的窗口變窄了。
等到了今天,移動終端的小屏特徵帶來了信息流和時間線,而這兩者一個來自於編輯推薦/演算法推薦,另一個則來自於用戶的關注關係。人們已經很難再去主動尋找信息,而是接受編輯、演算法認為適合他們的信息。
此時,移動互聯網下沉基本完畢,人們獲取信息的渠道更為集中,對於獲取信息的把控程度卻在下降。人們從信息的狩獵者逐漸變成獵物,難怪會被信息流控制自己的情緒。
讓渡信息窗口,直到成為演算法的鏡中人
其實互聯網發展的過程,可以被看做一個人類不斷讓渡信息窗口的過程。
從黃頁時期到搜索引擎的發展中,我們把部分信息窗口讓渡給了流量和金錢。廣告主和高熱度話題有權力佔據我們信息窗口的主要位置。而從發展引擎到信息流的發展中,社交關係和原生廣告加大了高熱度話題和廣告主在信息窗口中的佔比,而剩下的部分則被讓渡給推薦演算法和編輯。
信息流的出現,是這個讓渡的過程中最為關鍵的一步。我們雖然把信息窗口交了出去,卻獲得了更多、更具個性化的信息。黃頁時代的幾十萬個網站怎麼可能滿足人們豐富的需求?廣告主會鼓勵內容創造者創造更多內容,編輯和推薦演算法幫助我們找到最適合我們的內容。
這一切看似是非常良性的循環,可問題的關鍵在於:信息流和推薦演算法無處不在,它們已經不僅僅意味著我們瀏覽什麼,而對我們生活的很多方面都起到了關鍵性的作用。
Facebook的實驗,只是簡單的校驗了一下信息繭房的假說,結果卻發現信息流可能會影響到人們的情緒。實際在購物、旅行、音樂等等的選擇上,我們都會被信息流左右。
信息流影響了我們讀什麼新聞、看什麼電影、買什麼東西,而這些行為數據又被記錄下來,成為了自身畫像的一部分,也成了演算法構成的依據,某種程度來說,這一切都會讓我們和演算法中的自己越來越像。
演算法的第一要務是……
當人們和演算法中的自己越來越像(即使只是有這種可能性),演算法的價值觀、人工智慧的責任感這種論調就有了存在的必要。在內心深處,我們感受到了一種對自我把控的無力感。提出價值觀、責任感這種要求,就好像弱者對強者耍賴,要求籤訂一條互不侵犯的條約。
那麼問題是,難道就是為了我們自己的不安全感,信息流相關技術作為窗口的締造者,就有必要五講四美、三熱愛?
這時問題就上升到了更高形態:成為健康美好正直的人,是一種普世的價值觀。可沒人有權力阻止另一個人成為猥瑣陰險低俗的人。

如果演算法承擔了教育人性工作,不顧高中生的興趣標籤是王者農藥,在內容平台推薦數學題,在電商平台推薦《三年模擬五年高考》。以前的「我可能喜歡」、「我可能感興趣」、「和我一樣的人都在看」全都變成「你需要看」、「為了身體健康你最好買這個」「比你優秀的人看了這些」。
那樣的確是價值觀很正,可這行為真的正確嗎?
郭德綱說過,相聲的第一要務是教育人,好不好笑沒關係。
到底是誰沒有價值觀跟責任感?
所以說了這麼多,答案是演算法不該有價值觀,人工智慧不該有責任感嗎?
當然不是。
在以往的「技術責任事故」中,如果要追究責任,第一責任人往往是一位不作為的人類。如果說演算法該有價值觀,那價值觀也應該來自於人的作為。
- 第一,慎用作為信息窗口權力。不能再把一些莫名的條款隱藏在長長的用戶須知中,然後像Facebook一樣把自己的用戶作為實驗品。
- 第二,明晰人類和技術的權責劃分,做好人類的分內事。舉個例子,把鑒黃、鑒假這種事一味的交給人工智慧完全是不負責任的懶政,出了問題就責怪技術的不成熟而不是人的不作為,AI真的覺得很冤!
- 第三,給予用戶充分的知情權和選擇權。讓用戶在越來越小的信息窗口中清晰的知道信息為什麼會出現。比如不管原生廣告(自以為)做的多麼有趣、多麼原生,請務必標註上「廣告」二字。而給用戶推薦信息時,最好明確給出推薦理由,並給予用戶拒絕某一標籤或某一推薦來源的權力。不要在用戶點擊「不再推薦此類內容」后假裝看不見然後繼續推薦。
多的不說,只要人類能做到以上三點,演算法就會很有價值觀了。如果能從技術角度多進行一些優化,我們的信息流會變得非常讓人愉悅。
這篇文章的開頭,是一場Facebook主導的實驗,但在文章的最後,我想給大家介紹另一篇Facebook的研究成果。
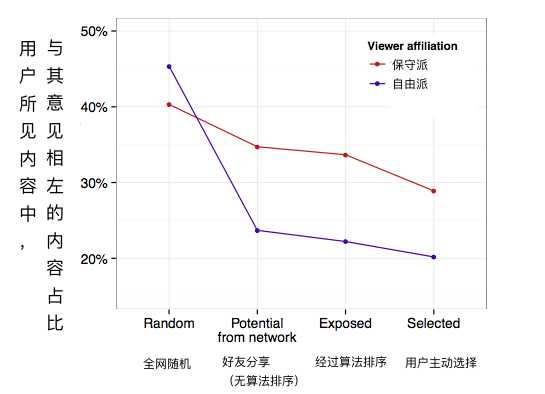
2015年(在那場實驗的兩年之後),Facebook研究了14年一年的用戶數據,為用戶和新聞鏈接的政治傾向都打了分,看看用戶會不會主動瀏覽跟自己政見有衝突的新聞。
結果如圖所示,Facebook隨機展示出的信息是一樣多的,但用戶們靠著自己的社交關係(自由派會關注更多的自由派,反之亦然)篩掉了一大部分政見相左的信息,靠自己的點擊又篩掉了一大部分,最後才是被演算法推薦篩選掉的。而演算法邏輯本身又部分成立在社交關係和用戶行為之上。結論就是,在信息展示這件事上,個人選擇比演算法的影響更大。
所以,即使信息繭房這種說法是存在的,但把成因最小的演算法推薦當做罪魁禍首,是不是在欺負演算法不會說話?