
編輯導語:隨著科技的快速發展,如今我們的生活越來越便捷,很多時候通過說話便有機器代替我們去完成一些事情,這便是語音技能帶給我們的好處。日常生活中,語音技能彷彿無處不在,小到手機、智能音箱,大到機器人,那麼,語音已經應該如何設計出來呢?

隨著語音交互的普及,我們首先用到的最多的就是語音技能,比如:我們讓智能音箱唱歌、查天氣、講笑話等,這些都是語音技能。今天,我們就來聊聊如何從零到一的設計一個語音技能。
1. 基礎信息介紹
在設計語音技能之前,我們首先要掌握技能用到的一些基礎定義,每家公司可能叫法上面會有區別,但是都大同小異。
1.1 基礎定義
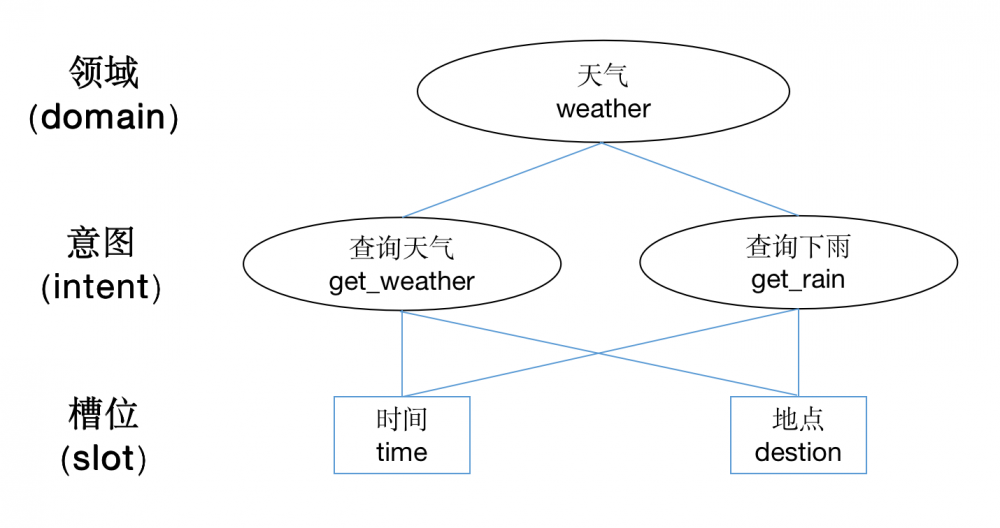
我們在聊聊語音技能常見的一些名詞和定義,主要有領域(domain)、意圖(intent)和槽位(slot),這些都是語音技能必不可少的一些參數內容。
1.1.1 領域
聽到這個詞,我們就感覺到了約束性,其實領域這個詞就是約束語音技能範圍的意思。一般一個語音技能,會有一個明確的領域,剩下的內容都在這個領域裡面做處理。
1.1.2 意圖
顧名思義就是判斷用戶具體要做什麼的意思,領域可以是一個大範圍的事情,而意圖是領域中的一個小分類。
比如:讓機器人跳舞是一個領域的事情,那麼「開始跳舞」和「停止跳舞」就是領域下的意圖的事情。意圖一般會非常明確,會有明確的邊界,在自然語言處理中屬於封閉域的問題。
1.1.3 槽位
根據槽位的有無,語音技能可以分為有槽位的和沒有槽位的。槽位一般就是指我們前面說到的實體詞,用來做信息抽取用的,補全和完善用戶的意圖。
比如:「唱首歌」就是沒有槽位的語音技能,只需要知道是唱歌的意圖就可以;而查天氣是常用的有槽位的語音技能,除了識別出這是一個查天氣的意圖之外,機器人還要知道要查什麼時間、什麼地點的天氣,時間和地點在這裡就是槽位信息。
有槽位信息的一般還會有默認槽位,就是沒有槽位信息的時候,直接使用默認的槽位信息,從而保證語音技能的正常。常見的就是「天氣預報」,默認的就是當地當天的天氣。
1.2 底層邏輯
再聊聊一下目前語音技能的底層邏輯,基於什麼能力實現的。
目前大部分做語音技能的公司,都是用正則表達式來寫的,就是基於一些文本規則,作為約束條件,篩選出來明確的意圖。抽取的槽位也是基於規則,或者窮舉的方式。
這樣做的好處是改動方便,以及改動后的影響好評估,而且冷啟動非常方便,甚至可以做到每天迭代;缺點也同樣明確,泛化能力弱,沒有學習能力。
也有一小部分公司已經開始使用演算法做語音技能了。
語音技能本質是一個意圖識別的事情,而意圖識別實際上又是一個分類問題,有基於傳統機器學習的SVM,基於深度學習的CNN、LSTM、RCNN、C-LSTM等。
槽位識別實際上是一種序列標記的任務,有基於傳統機器學習的DBN、SVM,也有基於深度學習的LSTM、Bi-RNN等。用演算法做的優點就是泛化能力強,有一定的學習能力;缺點就是成本高,適合複雜技能後期迭代的方向。

2. 語音技能的定義
在開始動手做語音技能的之前,要先對語音技能進行定義,知道技能的邊界,要有明確的反饋邏輯在裡面。我們這裡用「查天氣」這個爛大街,也是最典型的技能來舉例子。
2.1 定義技能
我們要明白為什麼做「查天氣」這個技能,以及要做到多細。
原因可能是我們就覺得這個技能很基礎,用戶都被教育過了,必須要有;也可能是我們看用戶的交互日誌,發現每天都有很多人有這個意圖,現在是未滿足狀態,值得單拿出來作為一個技能。
還可能是老闆覺得競爭對手有了,我們也要做。
假設我們是覺得是技能很基礎,必須要做。接下來我們就要考慮怎麼定義這個技能,需要注意以下幾點:
2.1.1 要明確技能的邊界,就是那些query是該技能要識別的,需要有一個明確的定義
這個看起來很容易,其實執行起來會很糾結,因為自然語言本身就有一定的歧異性。
就拿「查天氣」舉例子,比如:「今天該穿什麼?」、「明天能不能出去玩」算不算查天氣的意圖,都是要明確的。其實最讓你糾結的往往是模糊的語義,算作技能也不為錯,不算吧,又覺得用戶可能有這個意思。
所以明確的邊界的時候,有三種處理邏輯:
2.1.1.1 只處理特別明確的意圖,不care模糊的語義
比如:只處理「明天天氣」、「查一下天氣」等這樣的

2.1.1.2 模糊的意圖也一起處理,都歸為該技能
比如:「明天該穿秋褲嗎?」也屬於該意圖,和「明天天氣」一起處理

2.1.1.3 還有一種精細化的處理,把明確的意圖和模糊的意圖分開處理
比如:可以讓明確意圖直接執行,模糊意圖選擇反問,用戶確認后執行。用戶一旦確認后,以後這句話就歸位了明確意圖。
比如:用戶問「今天穿什麼出去好呢?」,計算機回答「您是不是想查詢今天的天氣?」,用戶回答「是的」,計算機回答「今天北京氣溫20度,適合……」;然後下次用戶問「今天穿什麼出去好呢」,計算機就可以回答「今天北京氣溫20度,適合……」,反之亦然。
當然如果模糊問的問法比較多,可以專門做意圖優化。

2.1.2 明確技能的領域、意圖和槽位的信息
就拿「查天氣」這個技能為例,領域我們一般設置為「weather」,但是意圖定義就會有兩種方案:
一種是簡單的,只有一個意圖,比如意圖也是「weather」;還有一種是精細化的處理,有若干餓意圖,比如「北京空氣質量?」算是「get_haze」,「今天會下雨嗎?」算是「get_rain」等,就是每個不一樣的問法,對應不同的意圖。
本質上越精細化的技能,給用戶的體驗會越好。

2.1.3 考慮技能內多輪的支持,以及支持的效果
由於自然語言先天是具有多輪屬性的,很多時候需要藉助上輪的信息,才能理解這句話,在做語音技能的時候,也要考慮到這方面的可能。
比如:用戶先說「明天天氣」,緊接著,用戶又說「後天呢?」,這個時候是否考慮支持,都需要在定義技能的時候明確。像用戶隔多久的多輪需要支持,支持的邏輯,我們這裡就不展開了。

定義好了技能,就知道了這個技能能幹什麼,方便後面的測試同學測試,也知道未來要迭代的方向。一般如果沒有數據支撐的話,建議先做最基礎的就可以,邊界越小越好。
2.2 觸發技能反饋
反饋這塊一方面依賴於產品底層的設計;另一方面依賴於產品形態,按照有無屏幕,可以簡單的分為兩種產品形態:有屏幕和沒有屏幕。這兩方面結合,才能設計出一個人性化的體驗。
產品的底層設計要考慮意圖要不要細化,比如:「今天有霧霾嗎?」和「今天天氣怎麼樣?」這兩種問法有沒有必要分開處理,設置不一樣的回復內容。
還要考慮如果槽位超出技能的邊界怎麼處理,比如:「三年後的天氣預報」,這個時候我們需要怎麼反饋,都是需要在語音技能定義的時候寫清楚。
具體怎麼展示以及怎麼回復,就要依賴於產品形態考慮。
有屏幕的可能更多的信息會通過屏幕展示,語音只是做到一個提醒的效果,有些場景甚至都不需要語音,而沒有屏幕的就要考慮語音播報的表達方式,要注意文字的長度,都播報那些內容,播報的先後順序,甚至播報的句式的豐富度都要考慮。
技能的反饋,是用戶直接能夠感受到的,其重要心怎麼強調都不為過,這塊可以參考語音交互的設計規則。

3. 數據的準備
前面說到的都是產品設計的時候要考慮到的問題,如果你把技能已經設計的差不多的時候,就可以準備這個意圖的訓練和測試數據,因為我們最終語音技能的開發是基於數據的,數據覆蓋的越全面,技能的效果越好。
無論訓練數據還是測試數據,簡單可以把數據分為兩部分,正例和反例。
3.1 正例數據
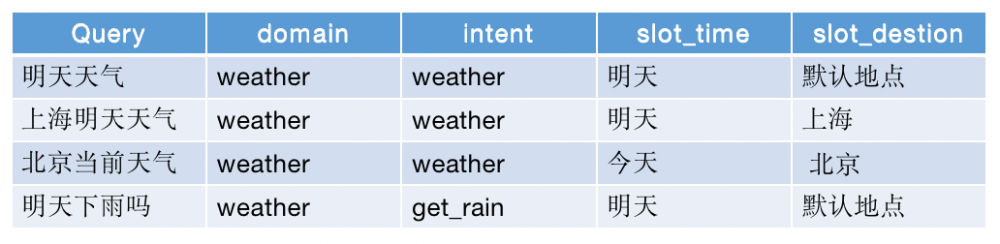
正例數據指的是正常的觸發文本,就是你設計的觸發query,像「明天天氣怎麼樣」、「天氣預報」、「查詢天氣預報」等,這些都是我們定義的「查天氣」的意圖。
一般在準備正例的數據時,最關心的是數據的來源,還有數據的豐富性。
如果是冷啟動的話,建議團隊內部,或者有專門的數據部門,進行人肉泛化,就是每個人自己寫幾條符合意圖的觸發query。
這裡亞馬遜在做智能音箱的時候有一個要求,就是每個意圖的正例訓練集的數據,不能少於30條(測試數據也一樣)。數據來源就是公司員工製造,數據豐富性就是依靠數據量標準約束。
如果是語音能力已經有了,每天都有大量的交互數據,我們就可以從真實的交互中拿數據。導出交互日誌需要逐一標註,從中找到屬於該意圖的數據。
這些數據的好處就是更加貼近用戶真實的情況,缺點就是成本會比較高,但一般都是可控的。
基於現有的交互數據標註,可以輕輕鬆鬆準備30該意圖的數據,建議越多越好,100條以上為最佳。數據來源就是用戶的交互,數據豐富性是依靠用戶的。
3.2 反例數據
反例數據指的是非該意圖的數據,就是除了正例數據,理論上所有的數據都是反例數據。像「明天要是不下雨就好了」、「我知道現在在下雨」、「我不想查天氣預報」等,這些都不是我們定義的「查天氣」的意圖。
很多時候,我們做語音技能的時候,是很容易忽略反例數據的。
反例數據最好是能夠有意圖相關的關鍵詞,數據量最好可以和正例數據一樣多。在準備反例數據的時候,要注意一些意圖相反的操作,比如:「我不想查天氣預報」,這是比較典型的反例數據。
往往反例數據比正例數據要難收集,尤其是高質量的反例數據,一般交互日誌是最好的資源。

正例數據可以保證準確率,而反例數據可以減少誤召回,提高召回率。
4. 語音技能的實現
訓練數據準備好之後,就是技能的實現了,這塊需要工程師的支持。有些公司是工程師直接寫語音技能的邏輯,有些公司是會提供一個平台,通過培訓,讓產品經理和運營同學也可以寫。
這裡就會用到一些基礎能力,當一句query傳過來,首先會使用中文分詞對這句話進行分詞。
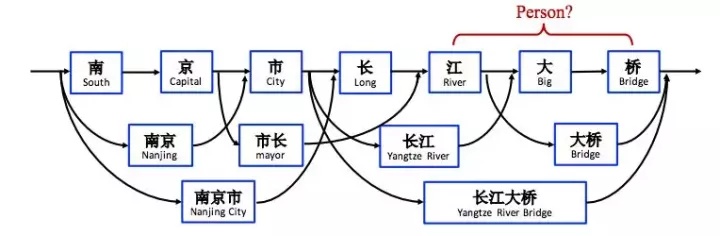
比如:「北京明天天氣怎麼樣」,會被分為「北京」、「明天」、「天氣」、「怎麼樣」,然後就是命名實體識別;比如:「北京」就是地點實體,「明天」就是時間實體,對應的就是語音技能的槽位。
最後就是匹配我們寫的正則表達式,這裡就不過多贅述,感興趣的同學可以搜搜看。
中文分詞:為什麼叫中文分詞呢?因為英文是以詞為單位的,詞和詞之間是依靠空格和標點隔開的,而中文是以字為單位的,一句話的所有字是連在一起的。
所以就需要演算法把一句話切分成有意義的詞,這就是中文分詞,也叫切詞,主要為了NLU後面處理做準備。了解鎚子手機的人可能知道上面有一個叫做「大爆炸」的功能,就是基於該演算法的。
這是NLU最底層的能力,一般都是用的開源的演算法,大家能力相差不大,基本可以保證準確率在90%以上。
命名實體識別:詞性標註是把每個詞的詞性標註出來,而命名實體識別是指識別文本中具有特定意義的實體,包括人名、地名、時間等。
一般來說,命名實體識別的任務就是識別出待處理文本中三大類(實體類、時間類和數字類)、七小類(人名、機構名、地名、時間、日期、貨幣和百分比)命名實體。
這個一般會根據本身業務的需求進行調整,不做明確的限制。
還有比較簡單的實現方式,就是通過窮舉實體+寫正則的方式,而不需要用到模型去做處理。
比如:「查天氣」這個技能,我們通過窮舉的方式,把表達地點和時間的詞語都窮舉出來,然後分別存到詞典裡面。最後使用這兩個詞典寫一些正則表達式,用來覆蓋我們準備的訓練集。
這樣做的的前提需要是實體詞是可以窮舉的,否者就會遇到召回率很低的問題。除了實現方法,我們還要考慮實現過程的效率,以及實現效果怎麼樣。
5. 測試驗收效果
一般的語音技能開發會比較快,開發完成之後就是驗收了,驗收最關心的指標是精準率和召回率。
5.1 驗收指標介紹
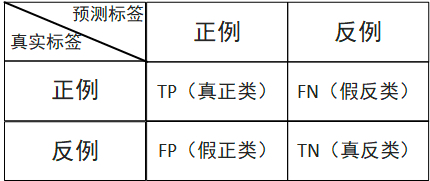
本質上就是計算機判斷了一次,然後人工判斷了一次,默認以人工判斷的為真實標籤,計算機判斷的為預測標籤,如下表:
5.1.1 精準率(Precision)
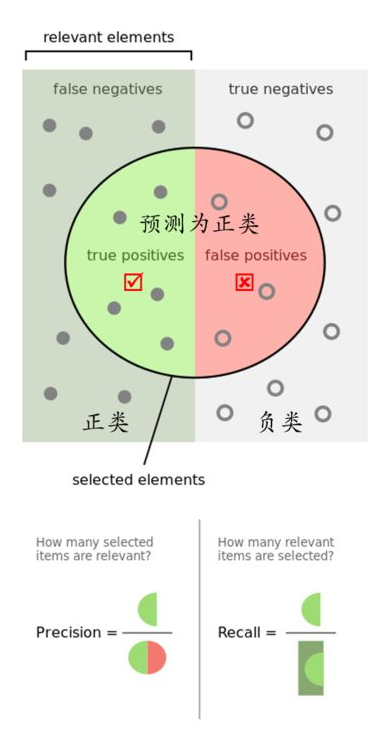
計算機認為對的數據中,有多少判斷對了。
精準率表示的是預測正例的樣本中有多少是真正類,預測為正例有兩種可能,一種就是真正類(TP),另一種就是假正類(FP),公式表示如下:
![]()
5.1.2 召回率(Recall)
的樣本中,有多少被計算機找出來了。
召回率表示的是樣本中的正例有多少被預測正確了。也只有兩種可能:一種是真正類(TP),另一種就是假反類(FN),公式表示如下:
![]()
其實就是分母不同,一個分母是預測標籤的正例數,另一個真實標籤的正例數。一般情況這兩個指標都會在0-1之間,越趨近於1,語音技能的效果越好。
5.2 驗收步驟
驗收這裡分為兩個步驟:一個NLU批量驗證;一個是端到端驗證,都可以用測試集來驗證。
NLU批量驗證就是把測試集的query,全部通過語音技能的邏輯跑一邊,一般用來驗證技能在NLU上面的效果。通常這一步只會測試新增的技能,單獨測試這個技能的效果,主要關心的是精準率和召回率,這一步理論上來說,必須這兩個指標都要達到95以上。
端到端驗證是模擬用戶正常使用,需要把技能放在整個語音鏈路上面,來觀察語音技能在實際情況中的表現。
通常這一步才會發現一些問題,比如:語音技能之間的衝突,甚至會發現ASR識別不對的情況。這一步主要關心響應時間、語音技能是否正常等情況。
測試一定要把好最後一道關卡,保證語音技能的精準率和召回率,同時也要測試技能之間優先順序的關係,是否技能之間會出現優先順序的問題。如果有多輪的語音技能,也要測試多輪的效果。
6. 總結
做一個語音技能,產品首先要有一個明確的定義,其次就是基於產品定義準備訓練集和測試集,然後基於訓練集完成技能的開發,最後使用測試集進行驗證。