
文章主要針對AI目前在各個比較熱門領域的應用現狀展開了梳理與分析,包含:計算機視覺、語音交互、自然語言處理和典型AI場景四個方面,與大家分享。

大家好,我是方舟,接下來我會出一個硬核知識系列,共三篇《AI產品經理必懂的硬知識》,從應用領域、常見概念與演算法、自我進階三個方面去闡述,這個系列算是榨乾了我多個筆記。第一篇咱們就來談談目前各個主流應用領域的現狀吧。有讀者反應我的文章過於「乾貨」,實在太長,要分好幾次看完,列個提綱吧。
一、計算機視覺(CV)
二、語音交互
(1)語音識別(ASR)
(2)語音合成(TTS)
三、自然語言處理(NLP)
四、典型AI場景
(1)智能機器人
(2)無人駕駛
(3)人臉識別(非手機端)
(4)視覺設計(手機端)
(5)自動文字編輯
一、計算機視覺(CV)
計算機視覺是一門研究如何使機器「看」的科學,就是指用攝影機和計算機代替人眼對目標進行識別、跟蹤和測量等機器視覺的應用,是使用計算機及相關設備對生物視覺的一種模擬,對採集的圖片或視頻進行處理從而獲得相應場景的三維信息,讓計算機具有對周圍世界的空間物體進行感測、抽象、判斷的能力。
計算機視覺在現實場景中應用價值主要體現在可以利用計算機對圖像和視頻的識別能力,替代部分人力工作,節省人力成本並提升工作效率。傳統的計算機視覺基本遵循圖像預處理、提取特徵、建模、輸出的流程,不過利用深度學習,很多問題可以直接採用端到端,從輸入到輸出一氣呵成。
1. 研究內容
- 實際應用中採集到的圖像的質量通常都沒有實驗室數據那麼理想,光照條件不理想,採集圖像模糊等都是實際應用中常見的問題。所以首先需要校正成像過程中,系統引進的光度學和幾何學的畸變,抑制和去除成像過程中引進的雜訊,這些統稱為圖像的恢復。
- 對輸入的原始圖像進行預處理,這一過程利用了大量的圖像處理技術和演算法,如:圖像濾波、圖像增強、邊緣檢測等,以便從圖像中抽取諸如角點、邊緣、線條、邊界以及色彩等關於場景的基本特徵;這一過程還包含了各種圖像變換(如:校正)、圖像紋理檢測、圖像運動檢測等。
- 根據抽取的特徵信息把反映三維客體的各個圖象基元,如:輪廓、線條、紋理、邊緣、邊界、物體的各個面等從圖象中分離出來,並且建立起各個基元之間的拓樸學上的和幾何學上的關係——稱之基元的分割和關係的確定。
- 計算機根據事先存貯在資料庫中的預知識模型,識別出各個基元或某些基元組合所代表的客觀世界中的某些實體——稱之為模型匹配,以及根據圖象中各基元之間的關係,在預知識的指導下得出圖象所代表的實際景物的含義,得出圖象的解釋或描述。
2. 瓶頸
- 目前在實際應用中採集到的數據還是不夠理想,光照條件、物體表面光澤、攝像機和空間位置變化都會影響數據質量,雖然可以利用演算法彌補,但是很多情況下信息缺失無法利用演算法來解決。
- 在一幅或多幅平面圖像中提取深度信息或表面傾斜信息並不是件容易的事,尤其是在灰度失真、幾何失真還有干擾的情況下求取多幅圖像之間的對應特徵更是一個難點。除了得到物體的三維信息外,在現實世界里,物體間相互遮擋,自身各部位間的遮擋使得圖像分拆更加複雜。
- 預知識設置的不同也使得同樣的圖像也會產生不同的識別結果,預知識在視覺系統中起著相當重要的作用。在預知識庫中存放著各種實際可能遇到的物體的知識模型,和實際景物中各種物體之間的約束關係。計算機的作用是根據被分析的圖象中的各基元及其關係,利用預知識作為指導,通過匹配、搜索和推理等手段,最終得到對圖象的描述。在整個過程中預知識時刻提供處理的樣板和證據,每一步的處理結果隨時同預知識進行對比,所以預知識設置會對圖像識別結果產生極大影響。
由於筆者本人是專門做AI CV這個方向產品的,因此未來的文章中關於CV的知識以及CV實際項目都會涉及很多。在之後的文章里針對視覺識別,特別是視覺識別裡面的明星應用人臉識別,我會很深入的去探討。其中人臉識別中所涉及的很多AI產品實現細節的拆解,從成像、預處理、算力估算到檢測、多目標、跟蹤、分割、識別、演算法精度測試模塊,如果弄懂弄透,再將這一塊體系延伸到車輛、動物等其他視覺類項目,基本原理都是類似的,可謂一通百通。
二、語音交互
語音交互也是非常熱門的方向之一,其實語音交互整個流程里包含語音識別、自然語言處理和語音合成。自然語言處理很多時候是作為單獨的一個領域來研究的,所以這裡暫且不展開,本文也將單獨介紹自然語言處理,所以此處只介紹語音識別和語音合成。
語音交互的最佳應用場景便是眼睛不方便看,或者手不方便操作的時候。「不方便看」比較典型的場景便是智能車載,「不方便操作」比較典型的場景便是智能音箱,這也是目前比較火的兩個細分方向。
一個完整的語音交互基本遵循下圖的流程:
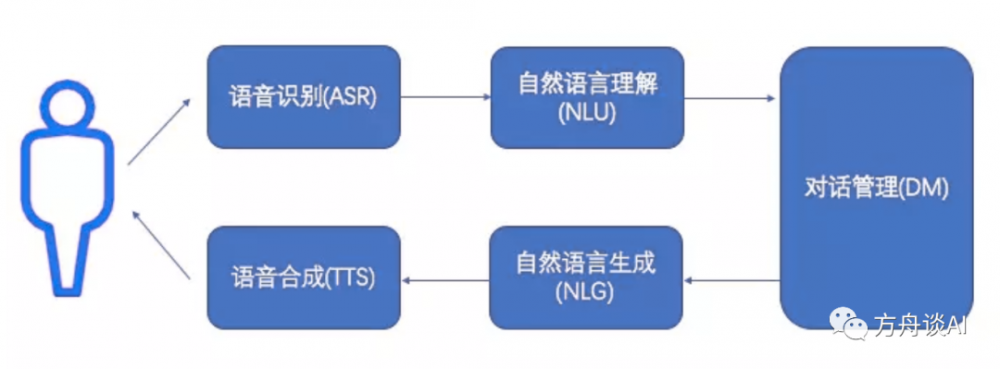
經典語音交互用例
1. 語音識別(ASR)
(1)研究內容
語音識別的輸入是聲音,屬於計算機無法直接處理的模擬信號,所以需要將聲音轉化成計算機能處理的文字信息。傳統的識別方式需要通過編碼將其轉變為數字信號,並提取其中的特徵進行處理。
傳統方式的聲學模型一般採用隱馬爾可夫模型(HMM),處理流程是語音輸入——編碼(特徵提取)——解碼——輸出。
還有一種「端到端」的識別方式,一般採用深度神經網路(DNN),這種方式的聲學模型的輸入通常可以使用更原始的信號特徵(減少了編碼階段的工作),輸出也不再必須經過音素等底層元素,可以直接是字母或者漢字。
在計算資源與模型的訓練數據充足的情況下,「端到端」方式往往能達到更好的效果。目前的語音識別技術主要是通過DNN實現的。語音識別的效果一般用「識別率」,即識別文字與標準文字相匹配的字數與標準文字總字數的比例來衡量。目前中文通用語音連續識別的識別率最高可以達到97%。
(2)衍生研究內容
- 麥克風陣列:在家庭、會議室、戶外、商場等各種環境下,語音識別會有噪音、混響、人聲干擾、回聲等各種問題。在這種需求背景下可以採用麥克風陣列來解決。麥克風陣列由一定數目的聲學感測器(一般是麥克風)組成,用來對聲場的空間特性進行採樣並處理的系統,可以實現語音增強、聲源定位、去混響、聲源信號提取/分離。麥克風陣列又分為:2麥克風陣列、4麥克風陣列、6麥克風陣列、6+1麥克風陣列。隨著麥克風數量的增多,拾音的距離,雜訊抑制,聲源定位的角度,以及價格都會不同,所以要貼合實際應用場景來找到最佳方案。
- 遠場語音識別:解決遠場語音識別需要結合前後端共同完成。前端使用麥克風陣列硬體,解決雜訊、混響、回聲等帶來的問題,後端則利用近場遠場的聲學規律不同構建適合遠場環境的聲學模型,前後端共同解決遠場識別的問題。
- 語音喚醒:通過關鍵詞喚醒語音設備,通常都是3個音節以上的關鍵詞。例如:嘿Siri、和亞馬遜echo的Alexa。語音喚醒基本是在本地進行的,必須在設備終端運行,不能切入雲平台。因為一個7×24小時監聽的設備要保護用戶隱私,只能做本地處理,而不能將音頻流聯網進行雲端處理。語音喚醒對喚醒響應時間、功耗、喚醒效果都有要求。
- 語音激活檢測:判斷外界是否有有效語音,在低信噪比的遠場尤為重要。
2. 語音合成(TTS)
(1)研究內容
是將文字轉化為語音(朗讀出來)的過程,目前有兩種實現方法,分別是:拼接法和參數法。
- 拼接法是把事先錄製的大量語音切碎成基本單元存儲起來,再根據需要選取拼接而成。這種方法輸出語音質量較高,但是資料庫要求過大。
- 參數法是通過語音提取參數再轉化為波形,從而輸出語音。這種方法的資料庫要求小,但是聲音不可避免會有機械感。
DeepMind早前發布了一個機器學習語音生成模型WaveNet,直接生成原始音頻波形,可以對任意聲音建模,不依賴任何發音理論模型,能夠在文本轉語音和常規的音頻生成上得到出色的結果。
(2)瓶頸
個性化TTS數據需求量大,在用戶預期比較高的時候難滿足。需要AI產品經理選擇用戶預期不苛刻的場景,或者在設計時管理好用戶預期。
三、自然語言處理(NLP)
1. 研究內容
自然語言處理是一門讓計算機理解、分析以及生成自然語言的學科,是理解和處理文字的過程,相當於人類的大腦。NLP是目前AI發展的核心瓶頸。整個NLP包括了句法語義分析、信息抽取、文本挖掘、機器翻譯、信息檢索、問答系統、對話系統等範疇。
NLP大概的研究過程是:研製出可以表示語言能力的模型——提出各種方法來不斷提高語言模型的能力——根據語言模型來設計各種應用系統——不斷地完善語言模型。自然語言理解和自然語言生成都屬於自然語言理解的概念範疇。
自然語言理解(NLU)模塊,著重解決的問題是單句的語義理解,對用戶的問題在句子級別進行分類,明確意圖識別(Intent Classification);同時在詞級別找出用戶問題中的關鍵實體,進行實體槽填充(Slot Filling)。
一個簡單的例子,用戶問「我想吃冰激凌」,NLU模塊就可以識別出用戶的意圖是「尋找甜品店或超市」,而關鍵實體是「冰激淋」。有了意圖和關鍵實體,就方便了後面對話管理模塊進行後端資料庫的查詢或是有缺失信息而來繼續多輪對話補全其它缺失的實體槽。
自然語言生成(NLG)模塊是機器與用戶交互的最後一公里路,目前自然語言生成大部分使用的方法仍然是基於規則的模板填充,有點像實體槽提取的反向操作,將最終查詢的結果嵌入到模板中生成回復。手動生成模板之餘,也有用深度學習的生成模型通過數據自主學習生成帶有實體槽的模板。
2. 應用場景
自然語言處理作為CUI(Conversational User Interface,對話式交互)中非常重要的一部分,只要是CUI的應用場景都需要自然語言處理髮揮作用。除此之外,機器翻譯、文本分類也都是自然語言處理的重要應用領域。但是自然語言處理的應用也是被吐槽最多的,經典的就是「智能客戶不僅沒增加效率,還降低了效率」,相比CV,NLP這一塊帶給人的直觀震撼目前來看確實要小很多。
3. 瓶頸
(1)詞語實體邊界界定
自然語言是多輪的,一個句子不能孤立的看,要麼有上下文,要麼有前後輪對話,而正確劃分、界定不同詞語實體是正確理解語言的基礎。目前的深度學習技術,在建模多輪和上下文的時候,難度遠遠超過了如語音識別、圖像識別的一輸入一輸出的問題。所以語音識別或圖像識別做的好的企業,不一定能做好自然語言處理。
(2)詞義消歧
詞義消歧包括多義詞消歧和指代消歧。多義詞是自然語言中非常普遍的現象,指代消歧是指正確理解代詞所代表的⼈或事物。例如:在複雜交談環境中,「他」到底指代誰。詞義消歧還需要對文本上下文、交談環境和背景信息等有正確的理解,目前還無法對此進行清晰的建模。
(3)個性化識別
自然語言處理要面對個性化問題,自然語言常常會出現模稜兩可的句子,而且同樣一句話,不同的人使用時可能會有不同的說法和不同的表達。這種個性化、多樣化的問題非常難以解決。
(4)NLP技術體系
這裡也總結了整個自然語言處理的技術體系,如下所示:
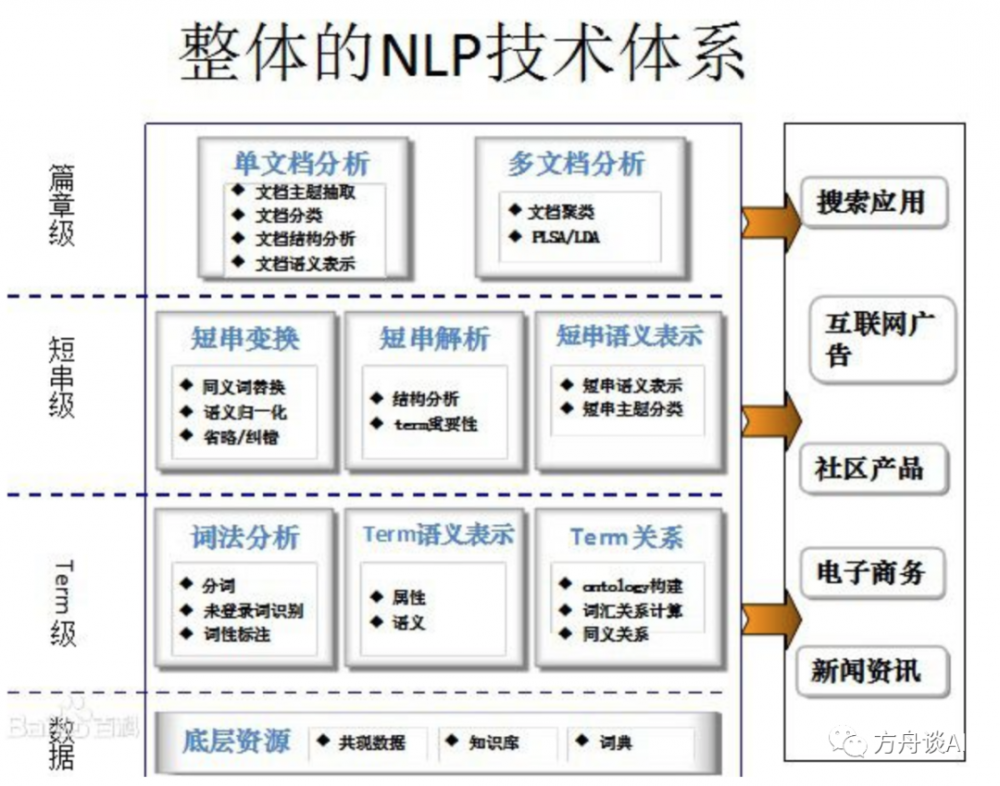
NLP技術體系
(5)產品體驗
自然語言識別:訊飛輸入法(PC軟體和手機APP),訊飛語記(手機APP),百度輸入法PC軟體和手機APP)
遠場語音識別(智能音箱):亞馬遜Echo,谷歌Home,蘋果HomePod
機器翻譯:google翻譯
多輪對話機器人:蘋果siri,微軟小冰,百度度秘,小i,小黃雞,圖靈機器人
(6)推薦閱讀材料
- 初學者如何查閱自然語言處理(NLP)領域學術資料:http://blog.sina.com.cn/s/blog_574a437f01019poo.html
- 語音識別技術原理:https://www.zhihu.com/question/20398418
- 科大訊飛新一代語音識別系統大揭秘:http://news.imobile.com.cn/articles/2015/1231/163325.shtml
- 自然語言處理(NLP)的基本原理及應用:http://blog.csdn.net/inter_peng/article/details/53440621
- siri工作原理詳解、siri技術解析:http://www.infoq.com/cn/articles/zjl-siri/
- CSDN自然語言處理博客文章:http://so.csdn.net/so/search/s.do?q=%E8%87%AA%E7%84%B6%E8%AF%AD%E8%A8%80%E5%A4%84%E7%90%86&t=blog&o=&s=&l=
四、典型AI場景
剛才說到了,目前AI的研究主流三大領域:計算機視覺、語音交互和自然語言處理,相當於是人工職能的視覺、聽覺和大腦。最後我再分別講一下目前市場很火熱的幾個場景,這些細分場景也是基於上述三大領域的交叉來實現的,包括智能機器人、人臉識別、移動端圖片處理、自動編輯等。
1. 智能機器人
以分揀機器人為例,分揀機器人(Sorting robot),是一種具備了感測器、物鏡和電子光學系統的機器人,可以快速進行貨物分揀。電商平台的蓬勃發展,自動分揀機器人已得了廣泛的應用。亞馬遜,阿里巴巴和京東均已將智能分揀機器人應用在貨物分揀工作中,極大節省人工成本,號稱一小時可以完成18000單的分揀工作。延伸閱讀如下:
- 工業機器人分揀技術的實現:https://wenku.baidu.com/view/a2da4ed17f1922791688e8cf.html
- 快遞分揀無人化有哪些關鍵技術?:http://baijiahao.baidu.com/s?id=1572495116614945&wfr=spider&for=pc
- 物流機器人市場發展迅速,分揀機器人的工作原理介紹:http://www.xianjichina.com/news/details_45519.html
2. 自動駕駛
自動駕駛汽車(Autonomous vehicles;Self-piloting automobile )又稱無人駕駛汽車、電腦駕駛汽車、或輪式移動機器人,是一種通過電腦系統實現無人駕駛的智能汽車。自動駕駛汽車依靠人工智慧、視覺計算、雷達、監控裝置和全球定位系統協同合作,讓電腦可以在沒有任何人類主動的操作下,自動安全地操作機動車輛。
2017年7月6日,百度AI開發者大會現場連線視頻中「李彥宏乘坐無人駕駛汽車上北京五環」的消息刷爆了朋友圈,近期一條自動駕駛大巴深圳上路的新聞刷爆朋友圈,由海梁科技攜手深圳巴士集團、深圳福田區政府、安凱客車、東風襄旅、速騰聚創、中興通訊、南方科技大學、北京理工大學、北京聯合大學聯合打造的自動駕駛客運巴士——阿爾法巴(Alphabus)正式在深圳福田保稅區的開放道路進行線路的信息採集和試運行。讓這個焦慮的世界又多了一批焦慮的人–公交車司機。
沃爾沃根據自動化水平的高低區分了四個無人駕駛的階段:駕駛輔助、部分自動化、高度自動化、完全自動化:
- 駕駛輔助系統(DAS):目的是為駕駛者提供協助,包括提供重要或有益的駕駛相關信息,以及在形勢開始變得危急的時候發出明確而簡潔的警告。如「車道偏離警告」(LDW)系統等。
- 部分自動化系統:在駕駛者收到警告卻未能及時採取相應行動時能夠自動進行干預的系統,如「自動緊急制動」(AEB)系統和「應急車道輔助」(ELA)系統等。
- 高度自動化系統:能夠在或長或短的時間段內代替駕駛者承擔操控車輛的職責,但是仍需駕駛者對駕駛活動進行監控的系統。
- 完全自動化系統:可無人駕駛車輛、允許車內所有乘員從事其他活動且無需進行監控的系統。這種自動化水平允許乘客從事計算機工作、休息和睡眠以及其他娛樂等活動。
這個領域的相關公司國外是家喻戶曉的特斯拉,國內做無人駕駛最不錯的是百度。百度無人駕駛車項目於2013年起步,由百度研究院主導研發,其技術核心是「百度汽車大腦」,包括高精度地圖、定位、感知、智能決策與控制四大模塊。
其中,百度自主採集和製作的高精度地圖記錄完整的三維道路信息,能在厘米級精度實現車輛定位。同時,百度無人駕駛車依託國際領先的交通場景物體識別技術和環境感知技術,實現高精度車輛探測識別、跟蹤、距離和速度估計、路面分割、車道線檢測,為自動駕駛的智能決策提供依據。
特斯拉(Tesla),是一家美國電動車及能源公司,產銷電動車、太陽能板、及儲能設備。Tesla 的計劃是通過不斷迭代輔助駕駛技術,使之最後升級成為無人駕駛。停留在輔助駕駛階段時,需要駕駛員。駕駛員有完全控制權,可以反制或取消輔助駕駛的行為,完全對安全負責。
Google 無人駕駛是一步到位的,基本原則就是不需要人類干預,沒有駕照的人也可以單獨上車,上車就睡,乘客不承擔責任。樂視網汽車頻道於2010年8月20日正式上線,依託樂視網視頻方面的優勢,將豐富、精彩、實用的汽車內容以視頻的形式呈現給廣大的網友,內容涵蓋新車報道、行業新聞、試乘試駕、維修保養、原創汽車視頻、車模風采、消費維權、汽車賽事等欄目·精彩的視頻讓網友輕鬆享受汽車行業的視聽盛宴。不幸的是無人駕駛和智慧出行是趨勢,但是2017年並不是其爆發點,龐大的樂視帝國因為供血無人汽車崩盤了。
延伸閱讀包括:
- 自動駕駛汽車涉及哪些技術?:https://www.zhihu.com/question/24506695
- 什麼是汽車自動駕駛,如何通俗易懂地理解其功能及原理?:https://www.zhihu.com/question/54647152
- 乾貨!激光雷達技術和自動駕駛技術原理分析:http://www.21ic.com/app/auto/201705/721051.htm
- 自動駕駛技術原理介紹和未來的趨勢如何:http://www.elecfans.com/xinkeji/595666_2.html
- Google 無人駕駛介紹Ted視頻,有中文字幕:https://www.ted.com/talks/chris_urmson_how_a_driverless_car_sees_the_road
- 黃仁勛訪談 Elon Musk 提到Tesla 輔助駕駛原理https://youtu.be/uxFeUOstyKI
- 人工智慧在自動駕駛技術中的的應用:https://wenku.baidu.com/view/277ffb5cbb1aa8114431b90d6c85ec3a87c28baa.html
3. 人臉識別技術(非手機端)
人臉識別,是基於人的臉部特徵信息進行身份識別的一種生物識別技術。用攝像機或攝像頭採集含有人臉的圖像或視頻流,並自動在圖像中檢測和跟蹤人臉,進而對檢測到的人臉進行臉部的一系列相關技術,通常也叫做人像識別、面部識別。2017年被全面應用在手機解鎖中。人臉識別系統主要包括四個組成部分,分別為:人臉圖像採集及檢測、人臉圖像預處理、人臉圖像特徵提取以及匹配與識別。
人臉識別技術產品已廣泛應用於金融、司法、軍隊、公安、邊檢、政府、航天、電力、工廠、教育、醫療及眾多企事業單位等領域。隨著技術的進一步成熟和社會認同度的提高,人臉識別技術將應用在更多的領域。而這個行業湧現出了像湖南視覺偉業、北京曠視科技、北京商湯科技等一批優秀的企業。
延伸閱讀包括:
人臉識別系統原理:
- http://blog.csdn.net/zergskj/article/details/43374003
- 人臉識別系統的原理與發展:https://wenku.baidu.com/view/0c56a7bf3186bceb19e8bbf9.html
- 人臉識別主要演算法原理:http://blog.csdn.net/liulina603/article/details/7925170
- 簡話人工智慧 | 2分鐘看懂人臉識別的原理:http://baijiahao.baidu.com/s?id=1568919427558010&wfr=spider&for=pc
- 人臉識別技術公司十大排名:http://www.elecfans.com/consume/571535.html?1509154910
4. 視覺設計(手機端)
自拍類APP越來越多,結合人臉識別技術,可以在人的面部或頭部添加耳朵,鼻子,王冠等道具,識別鎖定人的面部或肢體,保證道具可以自動隨著人的移動而移動。
Instagram可以實現自動識別一張圖中設計元素,賦予另外一張圖作為濾鏡,可以設計出效果超贊的設計效果,把一張普普通的風景照變成梵高風格的油畫。
國內包括視覺設計類AI的APP遍布我們的手機之中,美拍、SNOW相機、Faceu激萌,B612、羞兔、IN、美咖相機、LINE camera等手機APP支持人臉自動識別,貓耳朵、兔耳朵、狐狸耳朵、豬耳朵隨你挑。
延伸閱讀包括:
- A Neural Algorithm of Artistic Style:https://arxiv.org/abs/1508.06576
- 自己搭建一個ostagram:https://zhuanlan.zhihu.com/p/22704865
5. 文字自動編輯
機器人寫稿已經不是什麼新鮮事了,早兩年國外還出過專門的資訊APP,內容全部由機器抓取並生成短消息,主要集中在體育、財經等領域。很多海外的傳統媒體都已經運用上了機器人寫作,因為人工智慧可以監測網路熱詞,所以比起對熱點時間的敏感度,機器人的反應更靈敏,響應速度更快。
機器人知道什麼會成為熱點,也能第一時間把熱點傳遞給受眾。在媒體行業,AI寫稿是未來的一個趨勢,特別是類似財報、體育快訊、股市消息等結構化、標準化的以數據為主信息,人工處理反而不如AI精準、高效。
這裡推薦試用的產品包括騰訊的Dreamwriter、百度的寫作大腦、新華社的「快筆小新」、今日頭條的「xiaomingbot」。
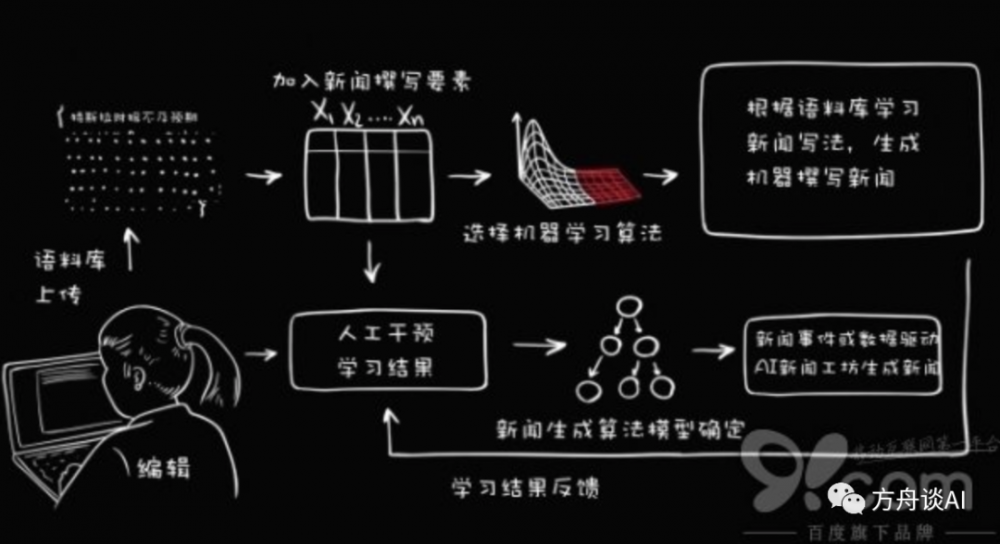
以百度產品為例的文字自動編輯流程
延伸閱讀包括:
- 紐約時報的「新媒體運營總監」,是一個叫Blossom的機器人:http://www.leiphone.com/news/201508/Ze9HOBijDnwIQIPE.html
- EditorAI:用人工智慧技術輔助記者編輯寫稿:http://news.91.com/mip/s5947c56e593b.html
- 人工智慧幫你寫論文,總有一款適合你!http://www.sohu.com/a/119470301_107743
以上,就是我目前總結的AI在各個領域的大體應用現狀,基本是比較全了,之後圍繞著各個技術點和產品設計,還將繼續深入的抽絲剝繭分享下去,敬請期待。
作者:方舟談AI,AI產品經理,公眾號&知乎:方舟談AI