
餘弦定理作為初中課本就學過的知識,AI產品經理將會把它運用到相似度計算當中。

世界上有些事物的聯繫常常超出人們的想象。
在數據採集及大數據處理的時候,數據排重、相似度計算是很重要的一個環節,由此引入相似度計算演算法。
但你知道我們在初中課本中學過的餘弦定理是如何完成相似度計算的嗎?
要揭開謎底,我們先來「三步走」。
一、TF-IDF單文本辭彙頻率/逆文本頻率值
1. 單文本辭彙頻率(TF: Term Frequency,是詞頻一詞的英文縮寫)
即一個詞在文中出現的次數。具體地講,如果一個查詢包含n個關鍵詞,它們在一個特定網頁中的詞頻分別是: TF1……TFn。
那麼,這個查詢和該網頁的相關性(即相似度)就是:T1+T2+…+Tn。
2. 逆文本頻率指數(Inverse Document Frequency,縮寫為IDF)
在詞頻的基礎上,要對每個詞分配一個「重要性」權重。
最常見的詞(「的」、「是」、「在」)給予最小的權重,較常見的詞(「中國」「北京」)給予較小的權重,較少見的詞(可能就是文章的主題詞)給予較大的權重。
這個權重叫做「逆文本頻率」,它的大小與一個詞的常見程度成反比。
概括地講,假定一個關鍵詞w在Dw個網頁中出現過,那麼Dw越大,w的權重越小,反之亦然。它的公式為logD/Dw,其中D是全部網頁數。
二、特徵向量
先看一下特徵向量的嚴格定義吧:
特徵向量是數學學科中的一個專業名詞,即線性變換的特徵向量(本徵向量)是一個非退化的向量。其方向在該變換下不變,該向量在此變換下縮放的比例稱為其特徵值(本徵值)。
一個線性變換通常可以由其特徵值和特徵向量完全描述,相同特徵值的特徵向量集合稱之為特徵空間。
嗯,這段話看看就好了。我們知道特徵向量是有方向的就好了。
接下來我們看看如何把一篇文章或一段話或一句話轉換成特徵向量。
首先,我們需要有一個辭彙表,比如是這樣的64000個詞:

其次,我們需要把輸入的文章或是段落或是語句進行分詞。目前市面常用的分詞器有很多,比如結巴分詞器、hanlp分詞器等,每種分詞器都有自己的優缺點,我們知道可以利用第三方的分詞工具幫助我們分詞就好了。
然後,就是最重要的一步,結合分詞結果,得到一個64000維的向量,比如是這樣的:

好了,現在對於每一個輸入,無論這篇文章多長,我們都能得到這樣一個向量。
例如向量1:[0,0.0034,0,0.00052,0…,0.034,…0.075]。
至此,我們已經完成了最重要的一步,把一篇篇文章變成一串串數字。是不是很有意思?
三、餘弦定理:向量距離的度量
好了,回顧一下餘弦定理。
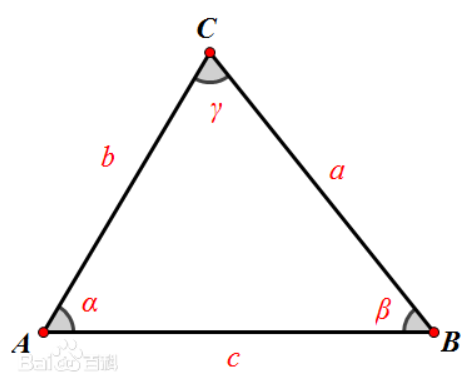
只看夾角A。
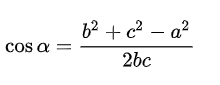
如果把三角形的兩邊b和c看成是兩個以A為起點的向量,那麼上述公式等價於:
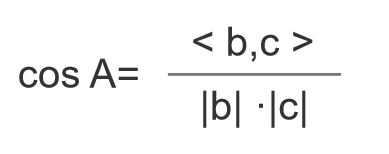
現在以兩篇文章為例,說明是如何進行計算的。
加入文章1和文章1對應的向量分別是x1,x2,…,x64000和y1,y2,…,y64000。
那麼他們夾角的餘弦等於:
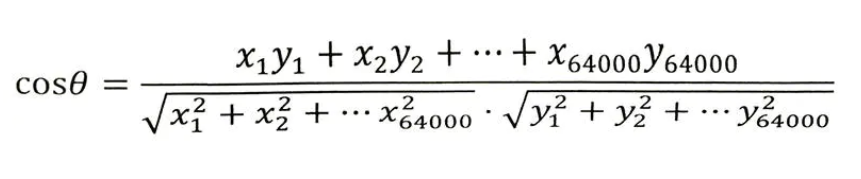
計算所得的餘弦取值在0和1之間,也就是說夾角在0度到90度之間。
現在,結論閃亮登場:
- 當兩篇文章向量夾角的餘弦等於1時,這兩個向量的夾角為零,兩篇文章完全相同;
- 當夾角的餘弦接近於1時兩篇文章相似,從而可以歸成一類;
- 夾角的餘弦越小,夾角越大,兩篇文章越不相關;
- 當兩個向量正交時(90度),夾角的餘弦為零,說明兩篇文章根本沒有相同的主題詞,它們毫不相關。
四、餘弦定理總結
餘弦定理:通過對兩個文本分詞,TF-IDF演算法向量化,對比兩者的餘弦夾角,夾角越小相似度越高,但由於有可能一個文章的特徵向量詞特別多導致整個向量維度很高,使得計算的代價太大不適合大數據量的計算。
餘弦定理的應用非常廣泛,我們在做智能問答系統中就用到餘弦定理做問題的相似度計算。
大概原理是這樣:用戶輸入問題1,系統對語料庫中的問題進行相似度計算,找出相似度最高的問題2,然後輸出問題2的答案。
可以看看下面的例子:
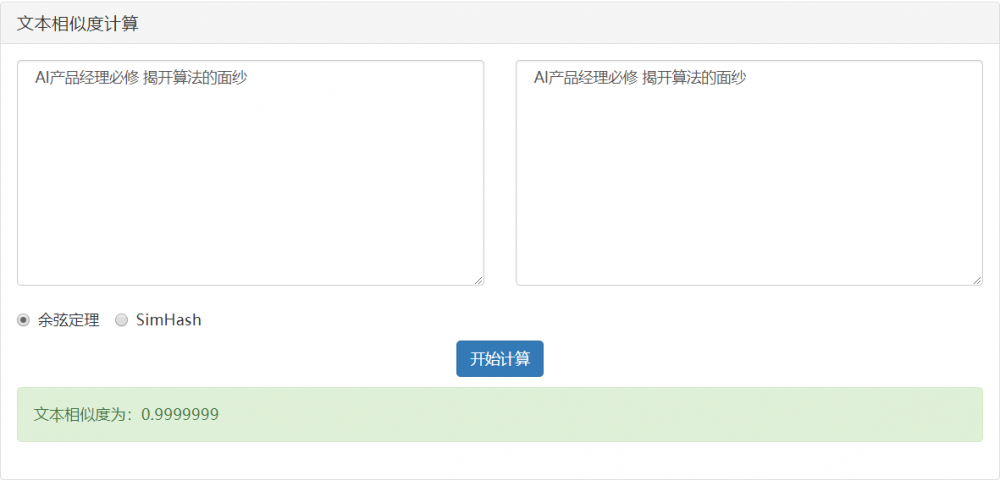
情況1:完全相同
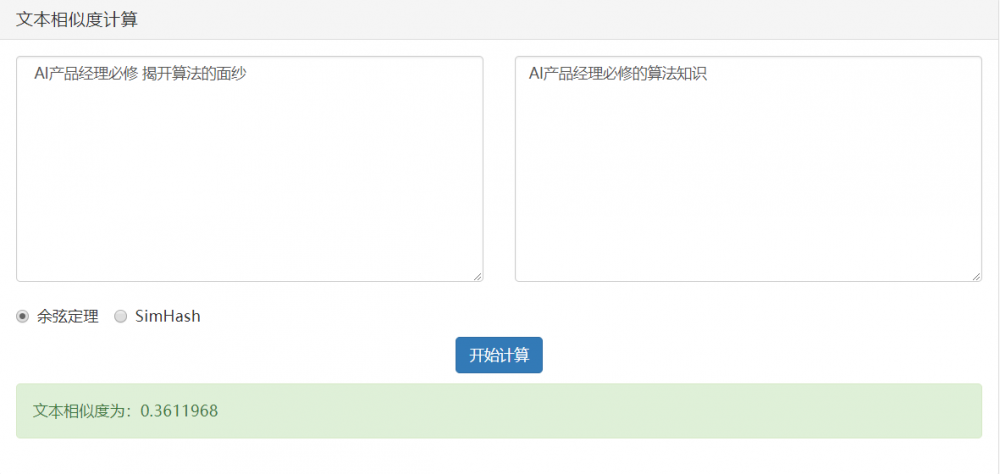
情況2:相似
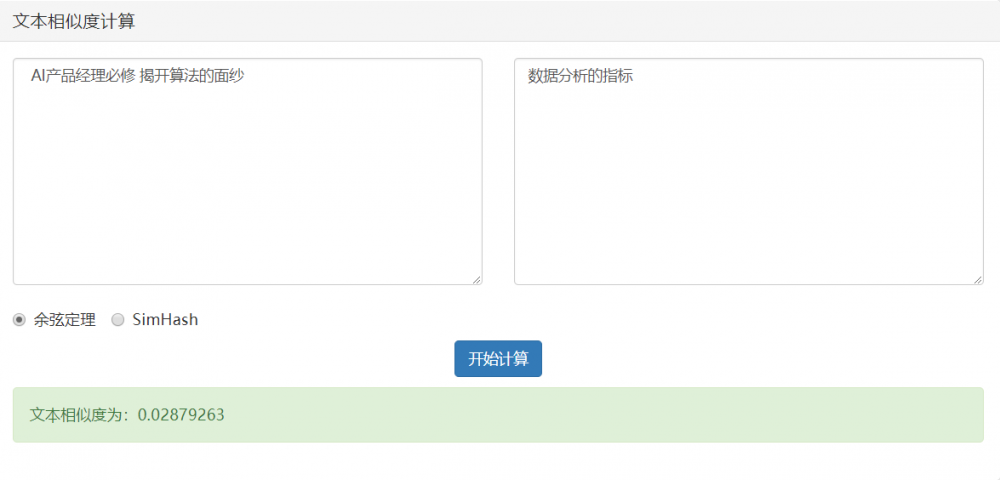
情況3:不相關