
編輯導讀:知識圖譜和機器學習,這兩個看似不相關的事物,放在一起會發生什麼樣的化學反應?本文將從五個方面,闡述機器學習如何與機器學習相互作用,希望對你有幫助。

某天中午吃完飯,和一位做大數據分析、機器學習建模相關的朋友聊天,談及到智能決策領域的增長點和突破口,目前智能決策領域已經基本業界標準化成型的,由產品&技術各組件組成的決策引擎體系,這套完整體系包括智能決策平台、批流化一體決策引擎、實時指標計算平台、風險核查平台、用戶畫像、數據服務、設備指紋等。
這些產品&技術已趨於成熟,均很難成為智能決策領域的突破口,機器學習、深度學習可以帶來一定增長點,不過要成為突破口比較難,畢竟模型對業務來說是個黑盒子,無法解釋。
就目前現狀而言,模型更多用於輔助決策,還無法放心地僅通過模型預測值就真正否決掉一個用戶或判斷是否欺詐、是否逾期等。人們往往更相信直觀可見的「證據」、人為積澱的經驗、亦或通過現有知識基礎推理衍生出的可解釋性結論,從這個角度上看,知識圖譜更可能成為突破口。
雖然圖譜目前還是個新手,距離真正成為突破口還有很大差距,特別是實時決策場景,毫秒級別內決策的要求對知識圖譜的性能將是個巨大的考驗,不過這不妨礙大家對她的青睞和期待。
通過關係進行風險傳導、智能通知預警和新營銷推薦,圖的可視化天然優勢、基於已有知識推理出新知識,通過圖表徵得出異常結構和異常點等,這些都是圖譜的優勢。基於現階段圖譜的優勢,結合上述提及的圖實時計算、實時決策的短板,筆者梳理出知識圖譜與機器學習結合的使用場景,並分析其如何賦能業務產生業務價值。
近3年從事智能風控決策領域,做過知識圖譜產品經理,做過智能決策、知識圖譜、模型管理&模型監控等相關的項目實施,因此除產品和技術外,得益於項目上的歷練,也有了一些些業務思維。
結合筆者在實際的業務應用場景和期間對知識圖譜、機器學習、用戶畫像、智能決策的理解、思考,總結出四類目前知識圖譜與機器學習的常見結合場景和結合方式。
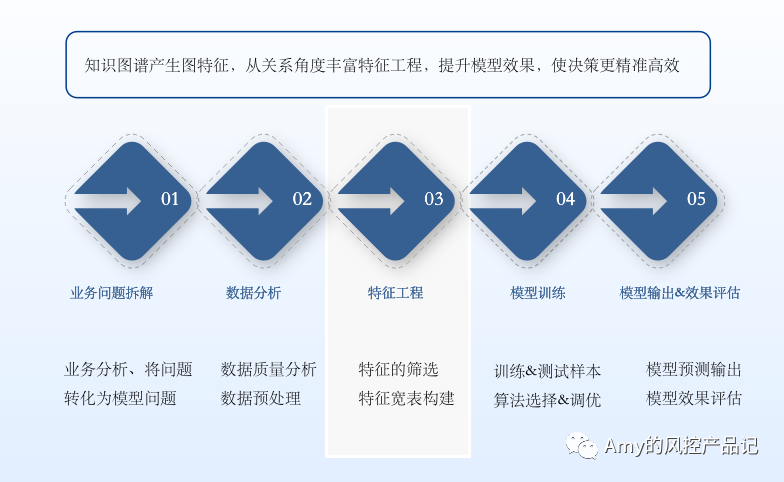
一、知識圖譜產生圖特徵,從關係角度豐富特徵工程,提升模型效果,使決策更精準高效
數據決定了模型的上限,特徵寬表則從各個緯度去刻畫數據特徵,在機器學習過程中,特徵工程的構建是建模最重要的環節之一。
常規的行為類、交易類、時序類、高頻類等特徵很容易從數據中挖掘,而關聯類特徵則需要數據分析師在腦海中推演可能的關聯情況和關係網路構成,且需要通過多次join來驗證,涉及三度及其以上的多度關聯時,無論是腦海推演過程抑或join邏輯都比較複雜。
如果事先構建好圖Schema(實體類型&關係類型及其屬性),通過知識圖譜直接抽取關聯特徵就方便很多,在實踐中證明,其餘條件保持不變的情況下,豐富圖特徵后,可以一定程度上提高模型的K-S、AUC值,某些用戶畫像、智能營銷推薦、信貸、反欺詐等場景下效果顯著。
通過圖特徵豐富特徵寬表,全面刻畫樣本表現情況,提高模型效果是目前知識圖譜和機器學習結合方式中最常見也是實踐最多的一種方式。
二、機器學習提供學習結果,豐富和增強圖譜知識,使圖譜更智能化
機器學習的本質是通過學習歷史數據和經驗得到未來的預測結果,通過學習而得到的預測結果本質也是一種「知識」,只是這類知識的準確性是個概率值。
當我們將機器通過學習而得來的知識輸入到圖譜中,在一定程度上豐富和增強圖譜知識,可以使圖譜更智能化。
例如,在原生圖資料庫中,我們知道用戶的基本信息,卻不知道這個人的信用分、行為分、欺詐分是多少,而機器學習提供的學習結果使我們對「人」這個實體的認知更豐富了,知識圖譜增強了知識儲備,這個時候再通過圖表徵(graph embading)得到更智能化的結果。
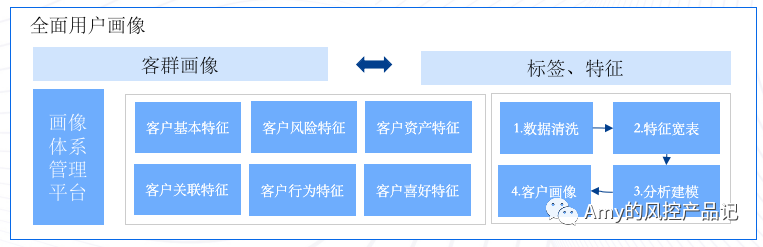
三、知識圖譜結合機器學習,基於已有數據輸出全用戶畫像
在刻畫全面用戶畫像場景下,知識圖譜和機器學習往往需要結合使用。
我們知道萬事萬物都由形形色色的關係構成,知識圖譜所產生的關於「人」實體的標籤和人與人之間的關係是「用戶畫像」的基本元素,機器學習、數據服務等產生的標籤也是用戶畫像的重要組成部分。
當然在全面用戶畫像場景下,遵循元素越多越好的原則:關聯關係越多越好,模型產生的標籤越多越好,數據緯度也是越多越好。
基於知識圖譜、機器學習、數據服務等綜合緯度的結合,讓我們更了解我們的用戶,更清楚他的喜好和習慣,然後更好地為他服務(讓他買買買)。

四、機器學習輔助社團劃分,交叉驗證定位欺詐團伙
第四種方式較適用於團伙欺詐場景,從業務視角看,一般社團劃分所得社團中涉黑佔比較高且社團成員數量適中的會被初步劃分為可疑社團,業務人員再從可疑社團中進行逐一排查得到欺詐團伙。
然而當知識圖譜進行社團劃分(常見的社團劃分圖演算法有:louvian、lpa標籤傳播等)的樣本中沒有黑樣本或黑樣本極少時,一方面圖譜只能通過原生關係進行聚類得到社團,另一方面業務人員初步的「可疑社團」範圍也無法圈定。
這個問題一般有三種解法,一是人為手工打標,通過人為經驗給樣本打標,該方式費時費力,一般不會採取除非資源足夠;二是通過制定規則(策略)識別出黑樣本或可疑樣本後進行打標;三是通過機器學習模型得到可疑樣本,並將閾值大於x(如0.6)的樣本默認打標再輸入到知識圖譜中進行社團劃分。
第三種解法即為本文中機器學習與知識圖譜結合的第四種方式—「機器學習產生樣本標籤,輔助圖譜社團劃分,尋找欺詐團伙」。
在欺詐團伙場景,還有種結合方式是:知識圖譜產生的可疑社團成員,通過模型來進行驗證。
例如圖譜產生某可疑社團中有200個成員,而模型對這200個成員的預測結果大多數為黑,則可大程度上認為該社團為欺詐社團。當然也可以反著來,通過模型預測得到的黑成員里,對應在圖譜上的劃分情況如何,有哪些成員是在圖譜的可疑社團裡面。通過這類交叉驗證的結合方式,可以幫助我們定位可疑社團、得到欺詐團伙。
五、知識圖譜產生黑名單,豐富機器學習黑樣本
前文提到的「大數據分析、機器學習建模相關的朋友」說起,目前機器學習的痛點之一是缺乏黑樣本、很多場景下建模無法獲取黑名單,這時就可以通過知識圖譜的關聯關係,通過一度、二度或多度關聯得到網路中的可疑名單,再加上業務專家經驗得到更多黑名單,擴展后的黑名單作為機器學習(這裡主要是有監督類)的標籤樣本輸入,一定程度上可以較大提高模型效果。
相關閱讀:
作者:Amy,公眾號:Amy的風控產品記(Amy_fkcpj)。