
本文介紹了AI多任務學習的定義、特徵、優勢和應用場景,表達AI多任務學習的發展需要向人類看齊。

提到AI領域的多任務學習,很多人可能一下子就想到通用人工智慧那裡了。通俗意義上的理解:就像《超能陸戰隊》里的大白這樣一種護理機器人,既能進行醫療診斷,又能讀懂人的情緒,還能像陪伴機器人一樣完成各種複雜任務。
不過大白畢竟只是科幻電影當中的產物,現有的AI技術大多還處於單體智能的階段,也就是一個機器智能只能完成一項簡單任務。
工業機器人中做噴漆的就只能用來噴漆;做搬運的只能用來搬運;識別人臉的智能攝像頭只能進行人臉。一旦人類戴上口罩,那就要重新調整演算法。
當然,讓單個智能體實現多種任務也是當前AI領域研究的熱點。
最近,在強化學習和多任務學習演算法上成績最好的是DeepMind公司的一款名為Agent57的智能體——該智能體在街機學習環境(ALE)數據集所有57個雅達利遊戲中實現了超越人類的表現。當然,多任務學習不止用在遊戲策略上。
相對於現階段的AI,我們人類才是能夠進行多任務學習的高手。我們既不需要學習成千上萬的數據樣本就可以認識某類事物,我們又不用針對每一類事物都從頭學起,而是可以觸類旁通地掌握相似的東西。
AI在單體智能上面確實可以輕鬆碾壓人類,比如可以識別成千上萬的人臉;但AI在多任務學習上面就要向人類的這種通用能力看齊了。
一、什麼是多任務學習
多任務學習(Multi-Task Learning,MTL),簡單來說:就是一種讓機器模仿人類學習行為的一種方法。
人類的學習方式本身就是泛化的,也就是可以從學習一種任務的知識遷移到其他的相關的任務上,而且不同的任務的知識技能可以相互幫助提升。
多任務學習涉及多個相關的任務同時并行學習,梯度同時反向傳播,利用包含在相關任務訓練信號中的特定領域的信息來改進泛化能力。
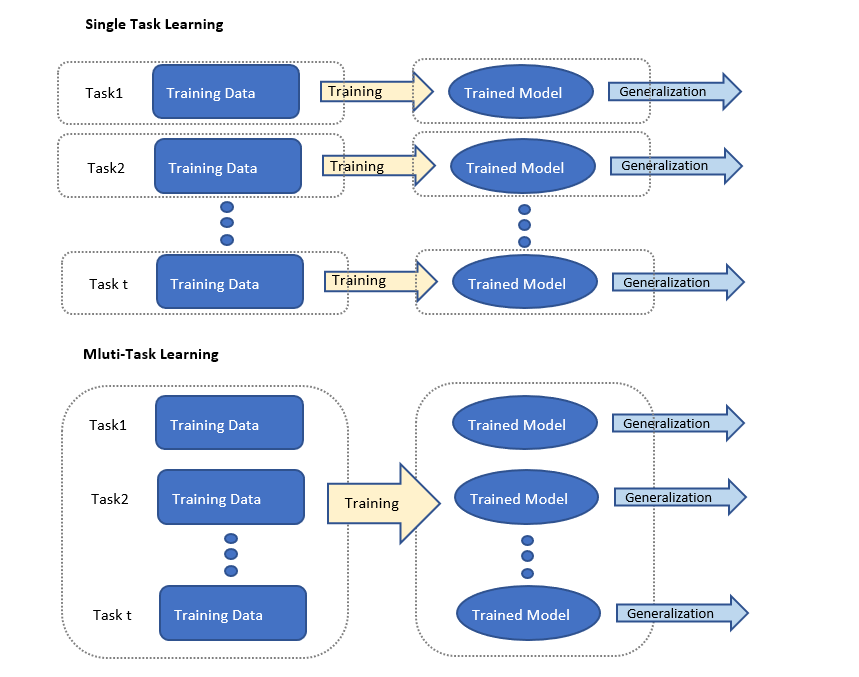
(單任務學習和多任務學習的模型對比示意)
做一個形象的類比:我們知道人類不如虎豹擅跑,不如猿猴擅爬,也不如鯨豚擅游;但是人類是唯獨可以同時做到奔跑、攀援和游泳的。用在人工智慧和人類智能上,我們通常認為AI更擅於在單一任務上表現優異並超越人類專家,如AlphaGo一樣;而人類則可能在各種任務上都能勝任。
MTL正是要讓人工智慧來實現人類的這種能力:通過在多個任務的學習中,共享有用的信息來幫助每個任務的學習都得到提升的一個更為準確的學習模型。
這裡需要注意的是多任務學習和遷移學習的區別:遷移學習的目標是將知識從一個任務遷移到另一個任務,其目的是使用一個或多個任務來幫助另一個目標任務提高,而 MTL 則是希望多個任務之間彼此能相互幫助提升。
二、了解MTL
1. MTL的兩個特徵
1)是任務具有相關性。
任務的相關性是說幾種任務的完成模式是存在一定的關聯性的,比如,在人臉識別中,除了對人臉特徵的識別,還可以進行性別、年齡的估算識別,或者,在不同的幾類遊戲中識別出共通的一些規則,這種相關性會被編碼進 MTL 模型的設計當中。
2)是任務有不同的分類。
MTL的任務分類主要包括監督學習任務、無監督學習任務、半監督學習任務、主動學習任務、強化學習任務、在線學習任務和多視角學習任務,因此不同的學習任務對應於不同的MTL設置。
共享表示和特徵泛化.
2. 理解MTL優勢的兩個關鍵
1)為什麼在一個神經網路上同時訓練多個任務的學習效果可能會更好?
我們知道,深度學習網路是具有多個隱層的神經網路,逐層將輸入數據轉化成非線性的、更抽象的特徵表示。
而各層的模型參數不是人為設定的,而是給定學習器的參數后在訓練過程中學到的——這給了多任務學習施展拳腳的空間,具備足夠的能力在訓練過程中學習多個任務的共同特徵。
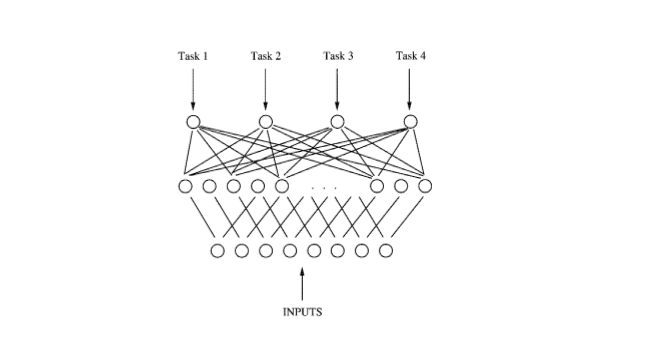
例如在上面的MTL的網路中,後向傳播并行地作用於4個輸出。由於4個輸出共享底部的隱層,這些隱層中用於某個任務的特徵表示也可以被其他任務利用,促使多個任務共同學習。多個任務并行訓練並共享不同任務已學到的特徵表示,這樣多任務信息就有助於共享隱層學到更好的內部表示,這成為多任務學習的關鍵。
2)那麼MTL是如何產生效果的?
MTL的方法中引入了歸納偏置(inductive bias)。
歸納偏置有兩個效果,一個是互相促進,可以把多任務模型之間的關係看作是互相先驗知識,也稱歸納遷移(inductive transfer)。
有了對模型的先驗假設,可以更好的提升模型的效果;另外一個效果是約束作用,藉助多任務間的雜訊平衡以及表徵偏置來實現更好的泛化性能。
首先,MTL的引入可以使得深度學習減少對大數據量的依賴。少量樣本的任務可以從大樣本量的任務中學習一些共享表示,以緩解任務數據的稀疏問題。
其次,多任務直接的相互促進,體現在:
- 多個模型特性互相彌補,比如在網頁分析模型中,改善點擊率預估模型也同時能促進轉化模型學習更深層的特徵;
- 注意力機制,MTL可以幫助訓練模型專註在重要特徵上面,不同的任務將為這種重要特徵提供額外證據;
- 任務特徵的「竊聽」,也就是MTL可以允許不同任務之間相互「竊聽」對方的特徵,直接通過「提示」訓練模型來預測最重要的特徵。
再次,多任務的相互約束可以提高模型的泛化性。
一方面:多任務的雜訊平衡。多任務模型的不同雜訊模式可以讓多個任務模型學到一般化的表徵,避免單個任務的過度擬合,聯合學習能夠通過平均雜訊模式獲得更好的表徵;
另一方面:表徵偏置。MTL的表徵偏好會造成模型偏差;但這將有助於模型在將來泛化到新任務。在任務同源的前提下,可以通過學習足夠大的假設空間,在未來某些新任務中得到更好的泛化表現。
3. 行業場景落地,MTL如何解決現實問題
由於MTL具有減少大數據樣本依賴和提高模型泛化表現的優勢,MTL正被廣泛應用到各類卷積神經網路的模型訓練當中。
首先,多任務學習可以學到多個任務的共享表示,這個共享表示具有較強的抽象能力,能夠適應多個不同但相關的目標,通常可以使主任務獲得更好的泛化能力。
其次,由於使用共享表示,多個任務同時進行預測時,減少了數據來源的數量以及整體模型參數的規模,使預測更加高效。
1)MTL在諸如目標識別、檢測、分割等場景為主的計算機視覺的應用:
臉部特徵點檢測:因為臉部特徵可能會受到遮擋和姿勢變化等問題的影響,通過MTL能夠提高檢測健壯性,而不是把檢測任務視為單一和獨立的問題。
多任務學習希望把優化臉部特徵點檢測和一些不同但細微相關的任務結合起來,比如頭部姿勢估計和臉部屬性推斷。
臉部特徵點檢測不是一個獨立的問題,它的預測會被一些不同但細微相關的因素影響。比如一個正在笑的孩子會張開嘴,有效地發現和利用這個相關的臉部屬性將幫助更準確地檢測嘴角。
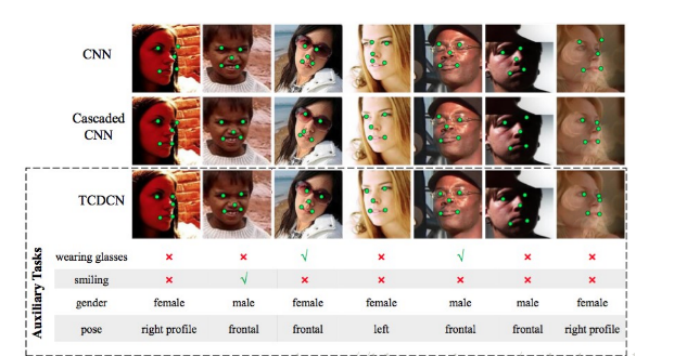
如上圖人臉特徵點檢測(TCDCN)模型,除了檢測特徵點任務,還有識別眼鏡、笑臉、性別和姿態這四個輔助任務;通過與其它網路的對比,可以看出輔助任務使主任務的檢測更準確。
MTL在不同領域有不同應用,其模型各不相同,解決的應用問題也不盡相同,但在各自的領域都存在著一些特點。
除上面介紹的計算機視覺領域,還有像生物信息學、健康信息學、語音、自然語言處理、網路垃圾郵件過濾、網頁檢索和普適計算在內的很多領域,都可以使用 MTL 來提升各自的應用的效果和性能。
比如:在生物信息學和健康信息學中,MTL被應用於識別治療靶點反應的特徵作用機制,通過多個群體的關聯性分析來檢測因果遺傳標記;以及通過稀疏貝葉斯模型的自動相關性特徵,來預測阿爾茨海默病的神經成像測量的認知結果。
2)在語音處理上的應用
2015年,有研究者在國際聲學、語音與信號處理會議(ICASSP)上分享了一篇《基於多任務學習的深度神經網路語音合成》的論文,提出一種多任務疊層深層神經網路。
它由多個神經網路組成——前一個神經網路將其最上層的輸出作為下一個神經網路的輸入,用於語音合成,每個神經網路有兩個輸出單元,共享兩個任務之間的隱藏層,一個用於主任務,另一個用於輔助任務,從而更好地提升語音合成的準確度。
3)在網路Web應用程序中
MTL可以用於不同任務共享一個特徵表示,學習web搜索中的排名提升;MTL可以通過可擴展分層多任務學習演算法,用於找到廣告中轉換最大化的層次結構和結構稀疏性等問題。
總體上來說,在這些MTL的應用領域中,特徵選擇方法和深度特徵轉換方法得到研究者的普遍應用。
因為前者可以降低數據維數並提供更好的可解釋性;而後者通過學習強大的特徵表示可以獲得良好的性能。
MTL正在越來越多的領域作為一種提高神經網路學習能力的手段被廣泛應用——這其實正是AI在眾多行業實際應用中的常態化場景。
我們可以最終溯源反思一下:人類之所以能夠具有多任務學習的靈活應用的能力,恰恰是因為所處環境正是處在多特徵、多雜訊的狀況之下。這樣必然要求我們人類必須能夠觸類旁通地進行先驗的學習能力的遷移。
而如果人工智慧僅僅停留在單體智能上面,為每一類知識或任務都建立一套單獨的模型,最後可能仍然只是一套「人工智障」的機械系統,鬧出「白馬非馬」這類的笑話來。
當AI未來真正既能在融會貫通的方面像人類一樣熟練,又能克服人類認知帶寬和一些認知偏見,那通向AGI的前路才可能迎來一絲曙光。
當然這條路還相當遙遠。
作者:藏狐;公眾號:腦極體