
文章回顧了近幾年NLP的發展歷程,從項目實施的兩個階段中帶我們梳理了NLP技術的應用演變。

第一個與大家分享的Case,基於NLP展開。分為3個部分,分別是NLP的發展、項目敘述、以及Lesson Learned。
講述NLP的發展,是為了更好地理解這門技術,為項目的展開做鋪墊。Lesson Learned是筆者總結整個項目下來自己的收穫。
筆者本身並非計算機課班,對理論知識的理解難免不深刻,以及可能會有偏差,請大家不吝指教。
目錄:
- NLP的發展
- 項目闡述
- Lesson Learned
一、NLP的發展
1.1 NLP的定義
The field of study that focuses on the interactions between human language and computers is called Natural Language Processing, or NLP for short. It sits at the intersection of computer science, artificial intelligence, and computational linguistics ( Wikipedia)
總結一下維基百科對NLP的定義, NLP關注人類語言與電腦的交互。
使用語言,我們可以精確地描繪出大腦中的想法與事實,我們可以傾訴我們的情緒,與朋友溝通。
電腦底層的狀態,只有兩個,分別為0和1。
那麼,機器能不能懂人類語言呢?
1.2 NLP的發展歷史
NLP的發展史,走過兩個階段。第一個階段,由」鳥飛派「主導,第二個階段,由」統計派「主導。
我們詳細了解一下,這兩個階段區別,
階段一,學術屆對自然語言處理的理解為:要讓機器完成翻譯或者語音識別等只有人類才能做的事情,就必須先讓計算機理解自然語言,而做到這一點就必須讓計算機擁有類似我們人類這樣的職能。這樣的方法論被稱為「鳥飛派」,也就是看鳥怎樣飛,就能模仿鳥造出飛機。
階段二,今天,機器翻譯已經做得不錯,而且有上億人使用過,NLP領域取得如此成就的背後靠的都是數學,更準確地說,是靠統計。
階段一到階段二的轉折時間點在1970年,推動技術路線轉變的關鍵人物叫做弗里德里克. 賈里尼克和他領導的IBM華生實驗室。(對IBM華生實驗室感興趣的朋友可以閱讀吳軍老師的《浪潮之巔》,書中有詳細講述。)
我們今天看到的與NLP有關的應用,其背後都是基於統計學。那麼,當前NLP都有哪些應用呢?
1.3 目前NLP的主要應用
當前NLP在知識圖譜、智能問答、機器翻譯等領域,都得到了廣泛的使用。
二、項目闡述
2.1 業務背景
說明:在項目闡述中,具體細節已經隱去。
客戶是一家提供金融投融資資料庫的科技公司。在其的產品線中,有一款產品叫做人物庫,其中包括投資人庫和創始人庫。
- 創始人庫供投資人查看,使用場景,當投資人考察是否要投資創業者,因此會關注創業者的學校(是否名校)、工作(大廠)、以及是否是連續創業者、是否獲得榮譽,如「30 under 30」。
- 投資人庫供創業者查看,使用場景:當創業者需要投資人,會考察投資人的投資情況。因此會關注投資者的學校(是否名校)、工作(大廠)、投資案例、投資風格等
我提供的服務,便是為這兩條產品線服務。因為本項目主要關注,相關人物的履歷信息,因此該項目代號為「人物履歷信息抽取」。
需要抽取的人物履歷信息,由5個部分組成:學校、工作、投資(案例)、創業經歷、獲取榮譽。
2.2 項目指標
項目指標包括演算法指標與工程指標。
2.2.1 演算法指標
演算法層面,指標使用的是Recall和Precision。為了避免大家對這兩個指標不太熟悉,我帶大家一起回顧一下。
我們先來認識一下混淆矩陣(confusion matrix)。混淆矩陣就是分別統計分類模型歸錯類,歸對類的觀測值個數,然後把結果放在一個表裡展示出來。矩陣中的每一行,代表的是預測的類別,每一列,代表的是真實的類別。
通過混淆矩陣,我們可以直觀地看到系統是否混淆了兩個類別。
我們可以舉一個混淆矩陣的例子:
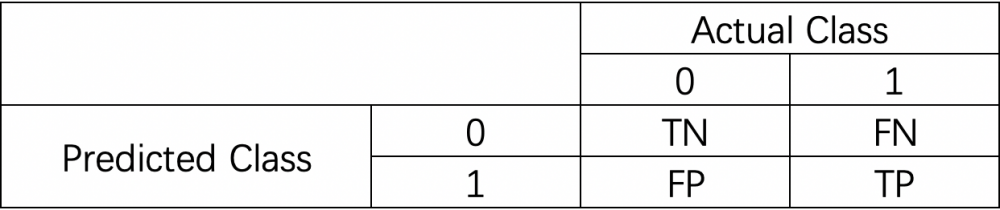
0代表Negative,1代表 Positve。
- TN:當真實值為0,且預測值為0,即為TN(True Negative)
- FN:當真實值為1,而預測值為0,即為FN(False Negative)
- TP: 當真實值為1,且預測值為1,即為TP(True Positive)
- TN:當真實值為0,而預測值為1,即為FP(False Positive)
除了上面,我們還需要了解下面三個指標,分別為Recall、Precision、和F1。
- Recall(召回率)是說我們的Predicted Class中,被預測為1的這個item的數量,佔比Actual Class中類別為1的item的數量。如果,我們完全不考慮其他的因素,我們可以將所有的item都預測為1,那麼我們的Recall就會很高,為1。但是在實際生產環境中,是不可以這樣操作的。
- Precision(精準率)是說,我們預測的Class中,正確預測為1的item的數量,佔比我們預測的所有為1item的數量。
- F1是兩者的調和平均。
Ok~了解了上面這些衡量演算法模型用到的基礎概念之後,我們來看看本項目的指標。
模型演算法指標為:recall 90;precision 60。
一個思考題?為什麼recall 90,precision 60?以及,為什麼沒有f1,或者說為什麼不將f設置為72,因為如果recall 90,precision60,那麼這種情況下,f1就是72嘛。
要回答上述問題,我們要從業務出發。需要記住,甚至背誦3遍。
為什麼,制定指標的時候,一定要從業務出發呢?
我們來舉一個很極端的例子,如果一個模型能做到recall90 precision90,是不是能說這個指標就很好了?
我相信絕大多數場景下,這個模型表現都是十分優秀。請注意,我說的是絕大多數,那麼哪些場景下不是呢?
比如說,癌症檢測。
假設,你目前在緊密籌備一個「癌症檢測」項目。對於每一個被檢測的對象,都有如下兩個結果中的任意一個結果:
- 1 = 實在抱歉,你不幸患上了癌症。
- 0 = 恭喜你,你並沒有換上癌症。
你同事告訴你了一個好消息,你們模型的在測試集上的準確率是99%。聽起來很棒,但是你是一個嚴謹認真的AI PM,所以你決定親自review一下測試集。
你的測試集都被專業的醫學人士打上了標籤。下面你測試集的實際情況
- 一共有1,000,000(一百萬張醫學影像圖)
- 999,000醫學影像圖是良性(Actual Negative)
- 1,000醫學影像圖是惡性(Actual Positive)
有了上述的數據,即我們模型驗證的GroundTruth,接著,我們來看看這個模型的Predicted Result。既然,我們上面學了confusion matrix,那麼我們回顧一下Confusion Matrix的兩個特徵,行代表Predicted class,列代表Actual class。讓我們看一下:
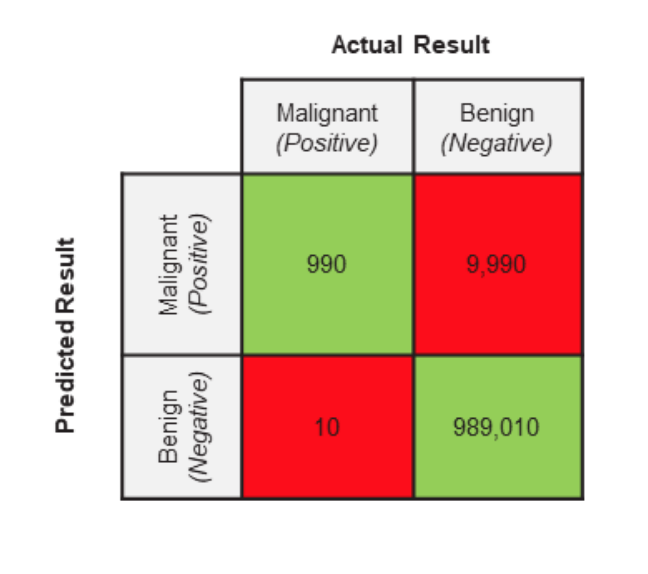
根據所學,實際應用一下:
- TP(實際是Malignant,預測是Malignant)
- FP(實際是Benign,預測是Malignant)
- TN(實際是Benign,預測是Benign)
- FN(實際是Malignant,預測是Benign)
看到這裡可能有點頭暈,沒關係,我馬上為大家總結一下:模型正確的判斷是1和3,不正確的判斷是2和4.
我們希望這個模型將醫學影像圖片是否為惡性腫瘤做好的區分,好的區分就是指的1和3。除此之外,其餘的都是錯誤的區分。
到這裡,我們再看看看模型的表現。
當同事告訴我們模型的正確率是99%的時候,她到底說的是什麼呢?我們來仔細分析一下哦~
🤔她說的是Precision嗎?
Precision回答的問題是,我們模型預測為1的樣本數量在實際為1樣本數量中的佔比。用公式表示
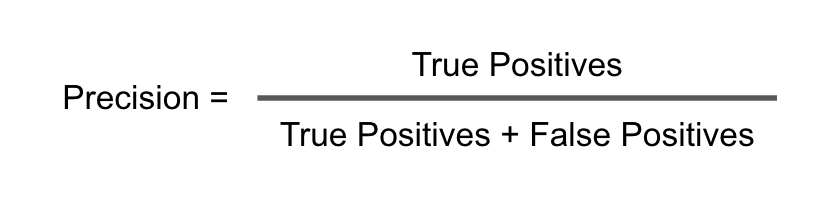
應用真實場景中,我們的準確率 Precision = 990 / (990 + 9,990) = 0.09 = 9%
🤔她說的是Recall嗎?

上述場景中,我們的召回率Recall = 990 / (990 + 10) = 990 / 1,000 = 0.99 = 99%
🤔她說的是Accuracy嗎?

上述場景中,我們的Accuracy是 Accuracy = (990 + 989,010) / 1,000,000 = 0.99 = 99%
從上面的指標,我們可以了解到我們的這個演算法模型有一個高的recall和高的accuracy,但是低的precision。
我們的演算法模型的precision只有9%。這就意味著被預測為maglignant的醫學圖像大多數都是良性。我們是不是可以這樣就說我們的演算法模型很垃圾呢?
並不是。實際上,在我們這個演算法模型裡面,recall的重要性是比precision高的。所以,儘管我們的precision只有9%,但是我們的召回有99%,這其實是一個很理想的模型表現。因為,患者有癌症,但是在檢查時候被漏掉,這種情況,是任何人都不希望發生的。
可能這個時候,你會有一個疑問,這個recall和precision的重要性如何來確定呢?好問題,讓我們來仔細看看。
首先,了解一下指標制定的原則:指標的制定取決於我們的商業目標,以及False Positive和False Negative帶來的損失。
🤔什麼時候recall比precision重要
當FN會帶來極大損失的時候,Recall會顯得非常重要。比如,如果將噁心腫瘤預測為良性,這就是非常嚴重的後果。
這樣的預測,會讓病人無法得到應該的治療,從而導致這位病人失去生命,並且這個過程是不可逆的!高的recall是我們希望盡量減少False Negative,儘管這樣會帶來更多的False Positive。但是通過一些後續的檢查,我們是能夠將這個FP排除的。
🤔那什麼時候precision比recall重要呢?
當FP會帶來很大損失的時候,Precision就顯得非常重要。比如在郵件檢測裡面。垃圾郵件是1,正常郵件是0,如果有很多FP的話,那麼大量的正常郵件都會被存儲到垃圾郵件。這樣造成的後果是非常嚴重的。
到了這裡,讓我們來回過頭去看看我們業務的recall 90 precision 60,我們會為什麼這樣制定?這還是得從業務背景談起。在我和團隊分享,如何評估客戶AI需求時候,一個很重要的步驟是,首先需要了解這個在沒有機器的條件下,他們是如何做這件事的?他們做這件事的判斷標準?以及具體的操作步驟。
只有在了解了這個的前提下 ,我們才可以根據這些domain knowledge來進行AI解決方案設計。提取人物履歷信息這些工作是由客戶的運營同學負責的,那麼客戶的運營同學之前是怎麼做的呢?他們會閱讀一篇文章,然後找出符合人物履歷標準的信息,做抽取,並進行二次加工。
注意哦,他們的重點是,需要做二次加工,這裡的二次加工指的是什麼呢?就是將人物的一些履歷信息進行整合。因此,其實對他們來說,召回不會最重要的,因為不斷有新的語料(文章)發布,他們總可以獲取相關人物的信息,但是從一篇好幾千字甚至上萬字的文章中,準確定位人物履歷有關的信息,就顯得非常重要,可以提升效率。
是的,效率, 是我們制定我們演算法指標的標準,提高召回,可以提高運營同學的效率。
下一個問題?為什麼不將f1設置為72呢?因為如果我們recall 90,但是precision 60,最後f1也是72,但是這是不符合業務場景需求的。
2.2.2 性能指標
以API的形式交付。對長度為1000字的文本,每秒查詢率(QPS)為10,一次調用在95情況下響應時間(RT)為3秒。介面調用成功率為99%。
讓我們拆解一下這個性能指標,首先說一下交付形式。
當前AI項目交付主要有兩種,API和Docker,各自適用於不同的業務場景。
QPS(Query Per Second)每秒查詢率是對一個特定的查詢伺服器在規定時間內所處理流量多少的衡量標準,在網際網路上,作為域名系統伺服器的機器的性能經常用每秒查詢率來衡量。對應fetches/sec,即美妙的響應請求數,也是最大吞吐能力。
RT響應時間是指系統對請求作出響應的時間。直觀上看,這個指標與人對軟體性能的主管感受是非常一致的,因為它完整地記錄了整個計算機系統處理請求的時間
2.3 項目實施
項目實施分為兩個階段,階段一的嘗試主要是使用規則,階段二的嘗試中,我們將策略從規則切換到了模型。從規則到模型的轉換,影響因素比較多,有隨著項目進展,項目組對項目難度的認識更加深刻的因素,也有數據集的積累更加豐富的原因。
2.3.1 階段一:規則
在項目中的階段一,我們的嘗試,主要在於規則。首先,我們來介紹一下,在機器學習裡面,什麼是規則。
那麼我們第一階段,使用規則具體是怎麼做的呢?
在第一個階段,我們整理出了3個文本:白名單、黑名單、打分詞。
先來說說這三個文本在我們規則中的使用邏輯,接著我會解釋為什麼,我們要這麼設計。
白名單:白名單是一個list,裡面有很多詞。當一句話中出現了屬於白名單詞典中的詞,我們就將這句話提取出來。
黑名單:當一句話中出現了這個詞,我們就將這句話扔掉。
打分詞:當一句話中出現了打分詞list中的詞,我們就給這句話加1分。(因為詞的權重不同,因此權重不一定都是1)
所以,為什麼我們要這樣設計呢?
我們首先來看看白名單,白名單中的典型辭彙有:畢業於、深造、晉陞等。大家可以發現,這些辭彙,有強烈的屬性表現,表現一個人物的履歷。因此,當出現了這些辭彙之後,我們就默認將這句話抽取(extract)出來。
黑名單中的典型辭彙有:死於,逝世、出席等。這些詞,明顯與人物履歷毫無關係。
最後,我們來看一下這個打分詞。在打分的設計邏輯上,我們使用了TF-IDF。同時,為了減少因為我們自己樣本量少,而帶來的負面影響,我們爬取了百度百科人物庫,通過TF-IDF,篩選出了幾百個和人物履歷描述相關的詞,並且人工對這些詞進行了打分。我們通過匹配一句話中出現的打分詞,來為一個句子打分。並且,我們可以通過調節句子得分的閾值,來調節我們命中人物履歷的句子。
通過規則,我們發現,模型的效果,在precision不錯,但是recall不夠好。通過分析bad case,我們發現模型的泛化性能差。
分析Bad Case的思路:
- 找出所有bad cases,看看哪些訓練樣本預測錯了?
- 對每一個badcase分析找出原因
- 我們哪部分特徵使得模型做了這個判斷
- 這些bad cases是否有共性?
- 將bad cases進行分類,並統計不同類別的頻數
這裡順便提一下,在我們分析bad case的時候,除了分析模型預測的錯誤之外,我們也會發現一些標註數據存在問題,在訓練集中,有人為標記錯的樣本很正常,因為人也不能保證100%正確。我們需要注意的是,這種標記錯誤分為兩類:
- 隨機標記錯誤,比如因為走神、沒看清給標錯數據
- 系統性標記錯誤,標錯數據的人,是真的將A以為是B,並且在整個標註流程中,都將A以為是B
對於隨機標註錯誤,只要整體的訓練樣本足夠大,放著也沒事。對於系統性標註錯誤,必須進行修正,因為分類器會學到錯誤的分類。
說明一下,關於Bad Case分析,吳恩達的課程都有講,如果想對這一塊知識,有進一步了解,可以自行進行學習。
💔階段一遇到的困難
通過對bad case的分析,我們發現通過規則中最大的問題是,模型無法分清動名詞。因此,導致precision非常地低。
舉2個例子:
A:小紅投資的運動裝公司西藍花。
B:小紅投資了運動裝公司西藍花。
第一句表達的主旨意思是運動裝公司,而第二句話表達的主旨是小紅進行了投資,因此從最開始對需要抽取句子的定義上來說,我們應該抽取第二句。但是,因為是打分機制,AB兩句都命中了「投資」,因此,均被抽取。
從這裡,就發現,我們的規則之路,基本上走到了盡頭,打分的方式是永遠無法將AB區分出來,於是,我們開始了我們下一段探索之旅。
2.3.2 階段二:模型
在階段一,我們講到了規則的一個弊端,就是規則無法區分詞性。
經過評估,我們還是打算使用模型來做,並且根據上一階段的發現,做對應的優化,在這裡,讓我們介紹一下「Part-of-Speech Tagging」
Part-of-Speech Tagging,也叫詞性標註。
詞性標註很有用,因為他們揭示了一個單詞以及其相臨近詞的很多信息。
我們看一下具體的用例。

根據POS,我們發現,」dog「是名詞,「ran」是動詞。是不是覺得這個方法剛好就能彌補我們上面談到的,模型無法分清動名詞這個困難。
因此,我們對所有數據,加了POS,然後放進了Bert,這裡還有一個小的tip,因為我們數據量其實是很小的,所以Bert只訓練了一輪。
既然這裡講到了Bert,那麼我也和大家一起重新複習一下Bert(我不是科班專業,也不是專門研究NLP方向的,所以我自己的知識積累有限,如果大家有更好的想法,歡迎交流討論90度鞠躬)
首先,我們了解一個概念「預訓練模型」。
預訓練模型就是一些人用某個較大的數據集訓練好的模型,這個模型裡面有一些初始化的參數,這些參數不是隨機的,而是通過其他類似數據上面學到的。
Bert呢,是一個Google開源的模型。非常的牛逼,那到底有多牛逼呢?這要從Bert的試用領域和模型表現效果,兩個維度來說說。
適用領域,Bert可以用於各種NLP任務,只需要在核心模型中添加一個層,例如:
- 在分類任務中,例如情感分析,只需要在 Transformer 的輸出之上加一個分類層
- 在問答任務中,問答系統需要接收有關文本序列的question,並且需要在序列中標記answer。可以使用 BERT學習兩個標記 answer 開始和結尾的向量來訓練 Q&A模型
- 在命名實體識別(NER),系統需要接收文本序列,標記文本中的各種類型的實體(人員、組織、日期等)可以用BERT將每個token的輸出向量送到預測 NER 標籤的分類層。
在part of speech 和Bert的加持下,我們模型的表現,達到了recall 90,precision 90。
暫且講到這裡吧~
三、Lesson Learned
其實從項目推進上,數據集管理上,策略分析上,感覺還有好多可以講,可以寫的,寫下來又感覺寫的太多了。之後,單開篇幅來寫吧
參考資料:
1. 語言本能
2. 數學之美
3. 智能時代
4. 2018年,NLP研究與應用進展到什麼水平了?
5. https://en.wikipedia.org/wiki/Confusion_matrix#cite_note-Powers2011-2
6. https://lawtomated.com/accuracy-precision-recall-and-f1-scores-for-lawyers/
7. [吞吐量(TPS)、QPS、併發數、響應時間(RT)概念 – 胡立峰 – 博客園](https://www.cnblogs.com/data2value/p/6220859.html)
8. [Bad Case Analysis](http://gitlinux.net/2019-03-11-bad-case-analysis/)
9. [【結構化機器學習項目】Lesson 2—機器學習策略2_人工智慧_【人工智慧】王小草的博客-CSDN博客](https://blog.csdn.net/sinat_33761963/article/details/80559099)
10. [5 分鐘入門 Google 最強NLP模型:BERT – 簡書](https://www.jianshu.com/p/d110d0c13063)
11. https://arxiv.org/pdf/1810.04805.pdf 《BERT: Pre-training of Bidirectional Transformers for Language Understanding》