
通過對人體系統進行建模,人工智慧技術已經取得了重大突破。儘管人工神經網路是數學模型,僅能粗糙地模擬人類神經元的實際運作方式,但它們在解決複雜而模糊的現實問題中的應用卻是深遠的。此外,在神經網路中模擬建模人腦的結構深度,為學習到數據背後更有意義的內涵開闢了廣泛的可能性。

在圖片識別和處理中,來自視覺系統卷積神經網路(CNNs)中的複雜且空間不變的神經元的靈感,也對我們的技術產生了很大的改進。如果您對將圖片識別技術應用於音頻頻譜圖感興趣,請查看我的文章「用於音頻處理的卷積神經網路(CNNs)和頻譜圖有什麼問題?」
只要人類的感知能力超過機器,我們就可以通過理解人類系統的原理來學習獲益。在感知任務方面,人類非常熟練,且在機器聽覺領域,人類的理解能力和當前的AI技術之間的對比尤為明顯。考慮到在視覺處理領域中受到人類系統啟發所帶來的好處,我建議我們可以通過神經網路應用於視覺領域相似的過程,運用在機器聽覺領域一定會獲益。
本文的流程框架
在本系列文章中,我將詳細介紹使用AI進行實時音頻信號處理的一個框架,該框架是Aarhus大學和智能揚聲器製造商Dynaudio A/S合作開發的。它的靈感主要來自於認知科學, 認知科學試圖將生物學、神經科學、心理學和哲學的觀點結合起來,以更好地理解我們的認知能力。
認知聲音屬性
也許關於聲音最抽象方式,在於我們作為人類如何理解它。雖然信號處理問題的解決方案必須在強度、頻譜和時間這些低級別屬性參數的範圍內進行處理,但最終目標通常是可認知的:以我們對聲音包含的意義認知方式轉換信號。
例如,如果希望以編程方式改變一段語音說話者的性別,則必須在定義其較低級別特徵之前,以更有意義的術語來描述該問題。說話者的性別可以被認為是由多種因素構成的認知屬性:語音的音高和音色、發音的差異、單詞和語言選擇的差異,以及對這些屬性如何與性別聯繫起來的理解。
這些參數可以用較低級別的特徵來描述,例如強度、頻譜和時間這些屬性,但只有在更複雜的組合中,它們才能形成高級別的意義表示。這形成了音頻特徵的層次結構,從中可以推斷出聲音的「含義」。人類聲音的認知屬性可以認為由聲音的強度、頻譜和統計特性的時間序列的組合模式來表示。
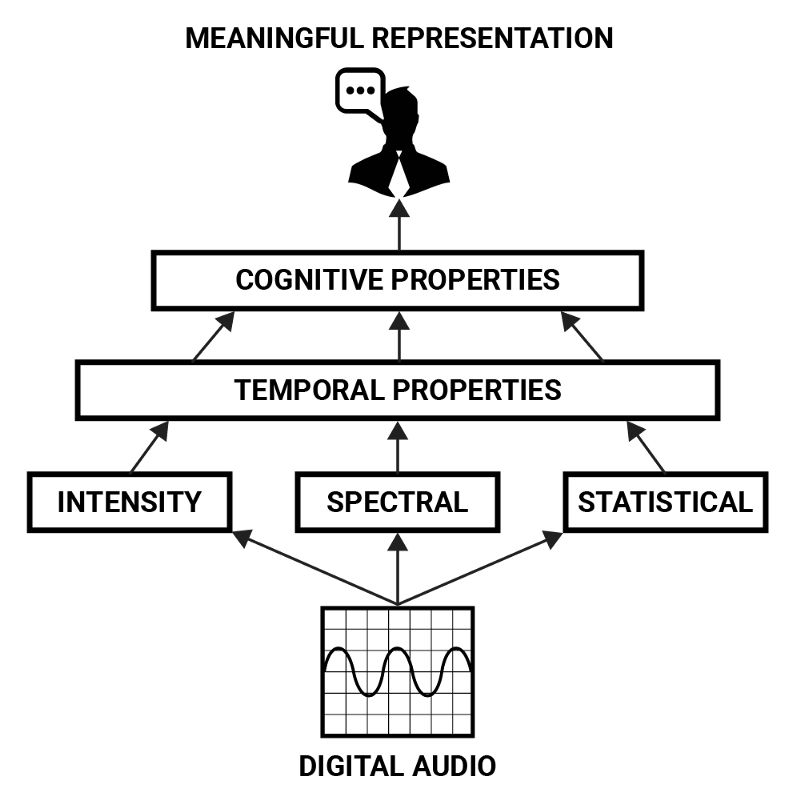
可用於從數字音頻中獲得含義的功能層次。
神經網路(NNs)非常擅長提取抽象的數據表示,因此非常適合檢測聲音中的認知屬性。為了構建一個基於此目的的系統,讓我們先來研究聲音在人類聽覺器官中的表現方式,我們可以用它來激發通過神經網路來處理聲音意義的表示。
耳蝸表示
人類聽覺始於外耳,外耳首先由耳郭組成。耳郭充當聲音頻譜預處理的一種形式,其中輸入聲音根據其相對於收聽者的方向而被修改。然後聲音通過耳郭中的開口進入耳道,隨後通過共振這种放大頻率(範圍為~1-6kHz)的方式,來改變輸入聲音的頻譜特性[1]。
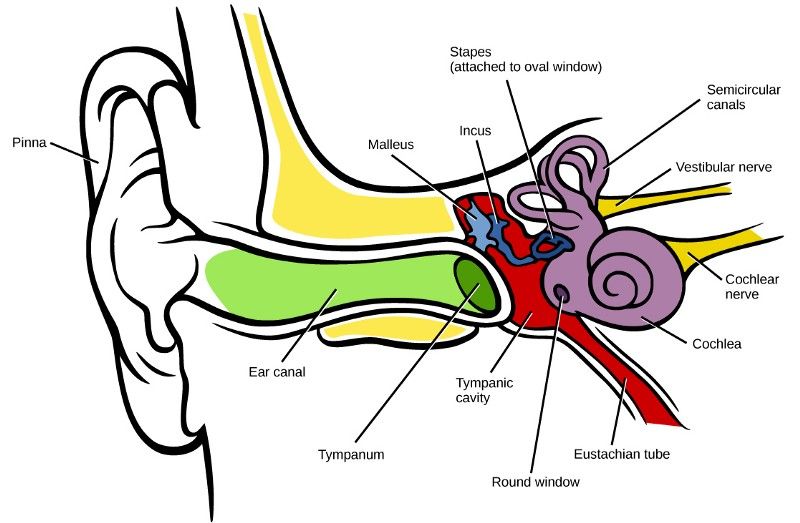
人類聽覺系統的圖解
當聲波到達耳道末端時,它們會激發耳膜,耳膜上附著了聽小骨(人體中的最小骨頭)。這些骨頭將壓力從耳道傳遞到內耳充滿液體的耳蝸內[1]。耳蝸對為神經網路(NNs)引導聲音的意義表示起很大作用,因為這是負責將聲振動轉換成人類神經活動的器官。
它是一個盤管,沿其長度上被兩個薄膜分開,即賴斯納氏膜和基底膜。沿著耳蝸的長度上, 有一排約3500個內毛細胞[1]。當壓力進入耳蝸時,它的兩個膜被壓下。基底膜的底部較窄且較硬,但在其頂點處較寬且鬆散,這使得沿其長度的每個位置在特定頻率下的相應更強烈。
簡單來說,基底膜可以被認為是一組連續的、和薄膜一樣長度的帶通濾波器,作用是把聲音分離到他們的譜分量。
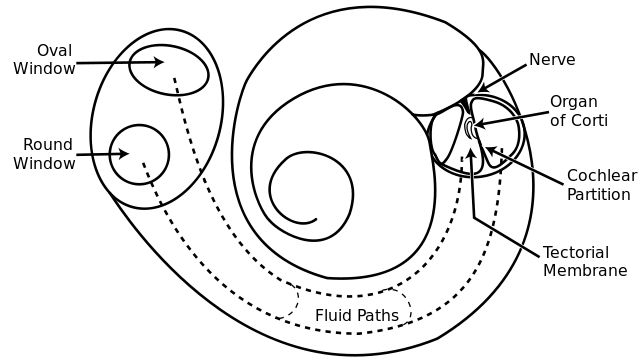
人類耳蝸的圖解
這是人類將聲壓轉變為神經活動的最基本的機制。因此,我們有理由假設,在用人工智慧建立聲音感知模型的時候,聲音的譜表示比較有利。因為基底膜上的頻率反應是以指數形式變化的,對數化的頻率表示可能是最有效的。一個這樣的頻率表示可以用gammatone濾波器組產生。這些濾波器被普遍應用於聽覺系統的譜濾波建模中,因為他們能夠估計產生自聽覺神經纖維的人類聽覺濾波器的脈衝響應,這是對一種叫做「revcor」函數的白雜訊的回應。
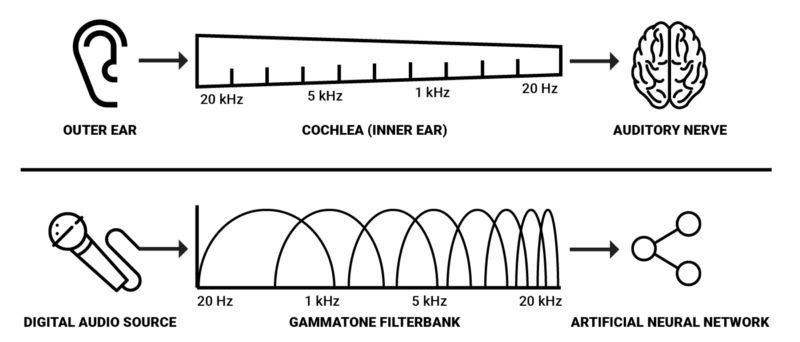
簡化的人類譜轉導和數字化譜轉導的對比
耳蝸有大約3500個內毛細胞,且人類能夠檢測到長度在2-5ms的聲音中的空隙,因此使用3500個分為2ms的窗口的gammatone濾波器進行譜分解看起來是用機器實現類人譜表示的最好的參數。然而,在實際場景中,我認為更少的譜分解也能在大多數分析和處理任務中達到理想的效果,同時在計算角度更為可行。
一些聽覺分析的軟體庫在線可用。一個重要的例子就是Gammatone Filterbank Toolkit by Jason Heeris.它不僅提供了可調節的濾波器,也提供了用gammatone濾波器進行聲音信號類譜分析的工具。
神經編碼
在神經活動從耳蝸移動到聽覺神經和上升聽覺通路的同時,一些工序在它到達聽覺皮層之前在腦幹核執行。
這些工序建立了一個表示刺激和感知之間相互作用的神經編碼。更多的關於這些細胞核內具體的工作的知識仍然是基於猜測或未知的,所以我將在他們如何發揮作用的高層次來介紹。
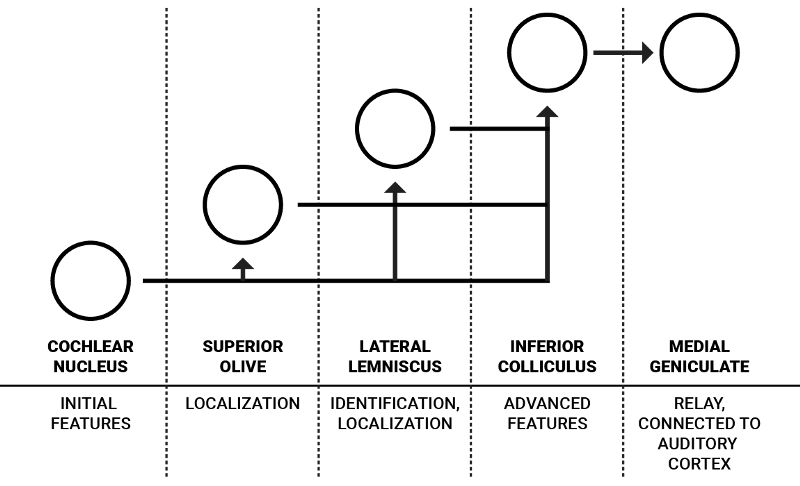
圖:簡化的上升聽覺通路(一隻耳朵)和設想功能的圖解
人類內在連接著的每隻耳朵都有一套這樣的核,但是簡單起見,我只闡述一隻耳朵中的流程。耳蝸核是為從聽覺神經到來的神經信號編碼的第一步。它包含許多有著不同特性,能夠完成聲音特徵的初處理的神經元。這些神經元中,一部分指向和聲源定位相關的上橄欖體,另一部分指向外側丘系核和下丘,通常與更高級的特徵相關。
J.J.Eggermont 在「Between sound and perception: reviewing the search for a neural code」 中如下詳細地闡述了從耳蝸核開始的信息流動過程:「腹側耳蝸核(VCN)提取並增強了在聽覺神經纖維的放電模式中多路復用的頻率和時間信息,並且通過兩種主要的通路來發送結果:聲源定位路徑和聲紋鑒別路徑。VCN的前部(AVCN)主要在聲源定位方面發揮作用,而且它的兩種bushy 細胞為上橄欖核(SOC)提供了輸入。在上橄欖核中耳間時間差(ITDs)和耳間水平差(ILDs)對於每種頻率分別映射。
聲紋鑒別路徑攜帶的信息是像母音一樣的復譜的一種表示。這種表示主要在腹側耳蝸核中由特殊種類的單元創造,這些單元也被叫做」chopper”神經元。聽覺編碼的細節很難被詳細說明,但是他們告訴我們,到來的頻譜的「編碼」形式可以提高對低層次聲音特性的理解,同時使在神經網路中處理聲音的代價更小。
譜聲音嵌入
我們可以應用非監督自動編碼器神經網路結構作為學習和複雜譜相關的普遍特性的一種嘗試。像詞嵌入一樣,在表示選中特徵(或一種更嚴格濃縮的含義)頻譜中發現共性是可能的。
一個自動編碼器經訓練能夠將輸入編碼為一種壓縮的表示法,這種表示法能重建回和輸入有高相似度的形式。這意味著一個自動編碼器的目標輸出就是輸入本身。如果一個輸入能夠在被重建的同時沒有很大的損失,神經網路就會學習在這種包含足夠多有意義的信息的壓縮內在表示法下編碼它。這種內在表示法也就是我們所說的嵌入。自動編碼器的編碼部分可以從解碼器解耦,來為其他應用生成嵌入。
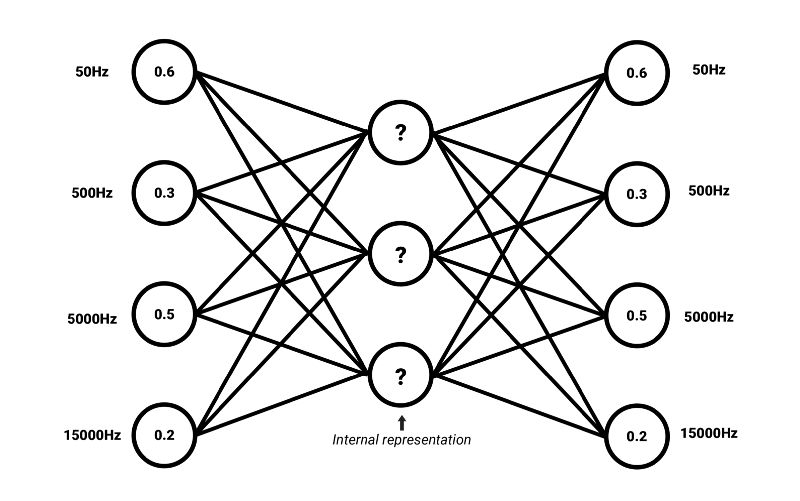
譜聲音嵌入的自動編碼器結構圖解
嵌入還有一個優點,就是他們通常比原始數據有著更低的維度。舉個例子,一個自動編碼器可以把有著3500個值的頻譜壓縮為一個長度為500的向量。簡單地說,這樣的向量的每一個值都可以描述像母音、聲震粗糙度或調和性的高層次的譜特徵——它們僅僅是例子,事實上一個自動編碼器生成的統計上的共同特徵的含義通常很難在原始語言中標記。
在下一個文章中,我們會拓展這個想法,採用新增內存來為聲音頻譜的時間產物生成嵌入。
這是我「用人工智慧進行聲音處理」的系列文章的第一部分。接下來,我們會討論聲音中的感覺記憶和時序依賴的核心概念。
參考文獻:
[1] C. J. Plack, The Sense of Hearing, 2nd ed. Psychology Press, 2014.
[2] S. J. Elliott and C. A. Shera, 「The cochlea as a smart structure,」 Smart Mater. Struct., vol. 21, no. 6, p. 64001, Jun. 2012.
[3] A.M. Darling, 「Properties and implementation of the gammatone filter: A tutorial」, Speech hearing and language, University College London, 1991.
[4] J. J. Eggermont, 「Between sound and perception: reviewing the search for a neural code.,」 Hear. Res., vol. 157, no. 1–2, pp. 1–42, Jul. 2001.
[5] T. P. Lillicrap et al., Learning Deep Architectures for AI, vol. 2, no. 1. 2015.
本文為 AI 研習社編譯的技術博客,原標題 :Human-Like Machine Hearing With AI (1/3)
作者:Daniel Rothmann
翻譯:悟空空、Glimmer
校對:鄧普斯•傑弗
原文鏈接:https://towardsdatascience.com/human-like-machine-hearing-with-ai-1-3-a5713af6e2f8
本文來源於人人都是產品經理合作媒體 @雷鋒網,翻譯@悟空空、Glimmer
題圖來自Unsplash,基於CC0協議。