
編輯導讀:AI改變了我們與機器互動的方式,影響了我們的生活,重新定義了我們與機器的關係。本文作者對人機交互的過程進行了分析拆解,對語音識別技術為什麼能把語音信號變成文字展開了詳細的說明,一起來看看~

背景:市面上有哪些搭載類似交互系統的產品?
微信的小微平台、淘寶的淘小蜜、釘釘的智能工作助理、百度的小度等等,既有面向C端消費者,又有面向B端企業主,如果要論商業化的潛力無疑目前機器人行業很大程度上C端的機器人產品已經幾乎被驗證無法實現盈利了,參考微軟小冰和siri,不過未來教育行業的幼兒機器人也許是一條光明大道。
更多的廠商已經轉向了幫助企業主實現數字化管理、智能化辦公而開發機器人能力,演化除了機器人的自定義平台,用於企業運維和管理。
智能語音交互系統簡單來講:就是語音識別+語義理解+TTS
雖然說的簡單,但是內部系統往往都比較複雜,每個點拆開來可能就足夠我們去研究迭代一生。為何說AI時代的重點和基礎是語音智能交互?在人工智慧時代,人們發現語音比文字輸入更能收集到有用的大量信息,這也是一種未來的主流形式。
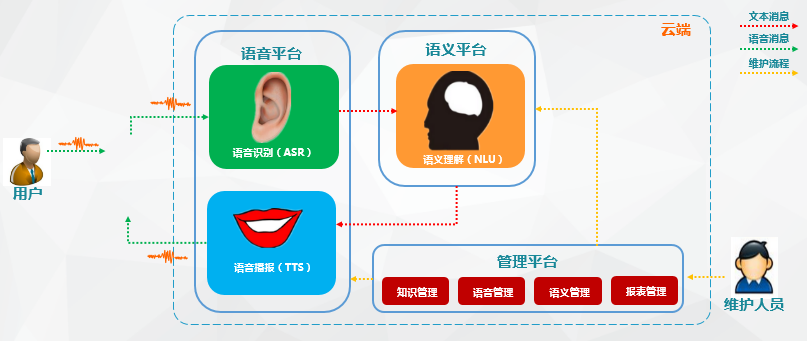
語音交互流程
智能語音交互系統概括起來就是一段音頻被機器人所吸收檢測,將識別到到的語音信號截取、轉換成語料庫里讀音信號頻率最為相近的文字(所以也有人形容語音識別其實是一種概率事件),而文本會通過特定介面進入語義分析引擎,進行分析。其中就可能要進行分詞、命名實體識別、詞性標註、依存句法分析、詞向量表示與語義相似度計算等NLP基礎功能。
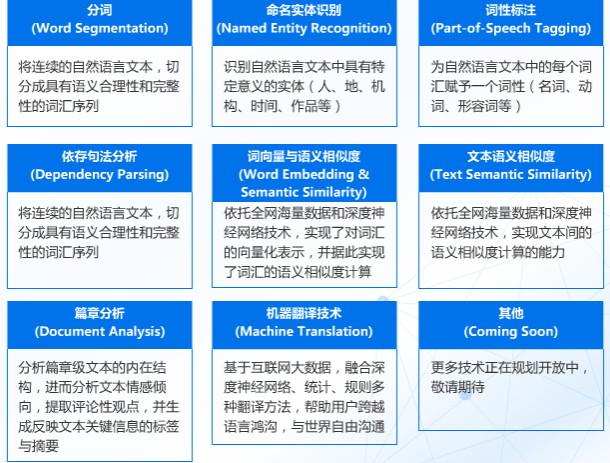
NLP基礎技術
一般情況下都會首先進行分詞分析:
例如:我想在房間里看電影
分詞:【我】【想】【在】【房間】【看】【電影】
這就是分詞的效果。而分詞的目的是為了找出文字中最重要的核心語義,命名實體識別功能(假如需要的話)
分詞:【我】【想】【在】【房間】【看】【電影】其中涉及到人物、地點、作品這些辭彙就可以自動被提煉出來,很多應用場景會需要用到這種信息分類識別的能力,比如人口錄入系統,只要將基本信息複製進去,自動分類此人的身份證號碼、地址、年齡等需求信息。
詞性標註:詞性標註可以幫助我們找到其中的名稱、動詞、 形容詞等。
依存句法分析的主要功能是能夠針對句子找出句子的核心部分,比如分詞:【我】【想】【在】【房間】【看】【電影】
經過詞性標註和依存句法分析之後可以找出這句話的觀點是:【在】【房間】【看】【電影】,這是整句話的核心。
從而我們可以通過檢索知識庫中和分詞內容相似度計算,並輸出相似度最高答案。
而詞向量與相似度主要能解決什麼問題呢?比如西瓜、呆瓜、草莓,在語義上哪兩個更像呢?
這個時候我們可以將這三個詞通過向量表達式工具和計算相似度來解決:
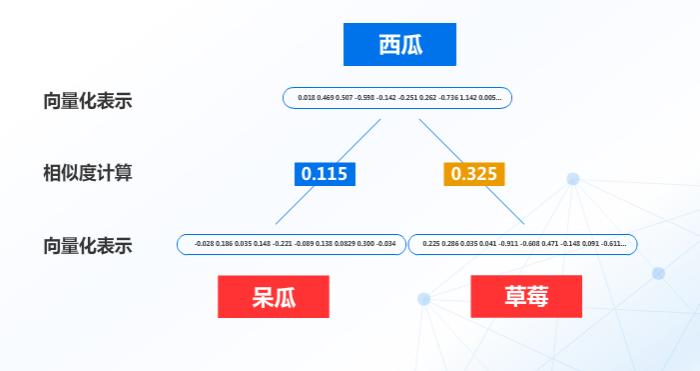
可以明顯的看出,語義上西瓜和草莓更相似,同屬水果,這樣就解決了大部分字面意思相近但是語義差別較大的情況,避免機器人錯誤理解人類的意圖。
回到題目,當我們的文本進入語義分析引擎,並經過上述的步驟后,計算相似度從而觸發設定閥值以上的答案即可請求伺服器發送正確答案給到終端處,如果需要機器人播報返回的文字時,可以接入TTS語音合成引擎(一般語音識別引擎就有這項功能)。

簡單的來講,語音交互系統流程框架大致如此,無論是軟體語音交互機器人還是實體機器人,本質上流程變動不大,根據業務需求會有些許差別,比如展示相關問,模糊問題引導,辭彙糾錯等需求就需要插入特定的流程。
通過上面所寫的內容,希望能讓大家大致了解市面上搭載智能語音交互系統的產品後台流程,也能明白一個簡單的對話框背後所涉及的技術高度。
四款人機交互系統:小i機器人、siri、漢娜、Echo。當然還有市面上眾多針對toB的機器人產品
今後真正的個人虛擬助理一定會搭載智能語音交互系統,並且會調用各種讓你意想不到的功能,從而成為你強大的私人秘書,能想象我們只需要說一聲幫我訂今晚到北京的機票,並通過語音密碼付款即可完成購票的整個流程嗎?這種場景真正商業化會在10年內大規模爆發。
說到這裡有必要給大家普及一下語音識別的一些細節內容,有人說:我很納悶,怎麼就能把語音變成文字?
在AI越來越普遍令大家感到新鮮的同時,一些專業名詞也讓大家開始熟悉起來,起碼也都能了解到一些術語所代表的含義。
例如:語音識別就是把語音信息變成文字的技術;自然語言處理就是能讓機器人理解人類通用語言的技術;人臉識別就是拍個照就能認出你是誰的技術。不能不說技術的普及,生活水平的提高會讓人們對技術基礎的理解程度也越來越高,接受能力也變得很高。
經典案例:90年代我國開始研究二維碼,但是大家並不熟悉,關鍵在於沒有產品使得二維碼變得普及,幾年前微信和支付寶開始率先使用二維碼支付后,二維碼迅速成為大街小巷最普及的東西,大家從一開始的質疑到將信將疑最後變成信任,這就是技術普及的力量,讓這種新鮮的技術變成一種社會的常識。
這篇文章我會詳細給大家解釋一下語音識別技術為什麼能把語音信號變成文字?
過程的第一部分就是發送一段語音信號,有點像是心電圖頻率的波動,下圖我們先介紹一下語音識別的整個流程,先有個概念。
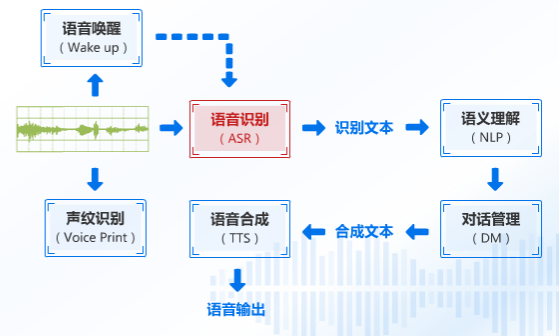
語音識別流程圖
這段音頻進入語音識別引擎之後,就會送出識別到的文本,我們將這個文本發送給語義分析並處理,進而得到相似度最高的答案,併合成文本發送到語音合成引擎之中進行語音輸出。
那麼重點來了這個【ASR】是怎麼讓語音變成文字的?
接下來我們繼續分解,看下圖:
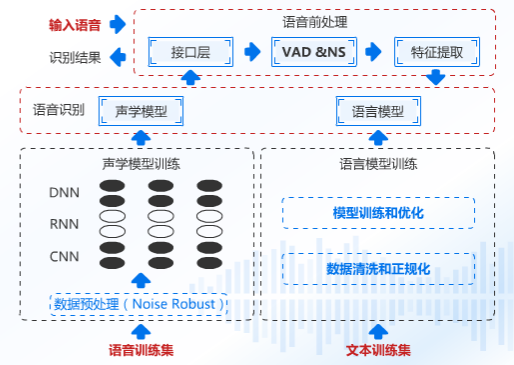
語音預處理
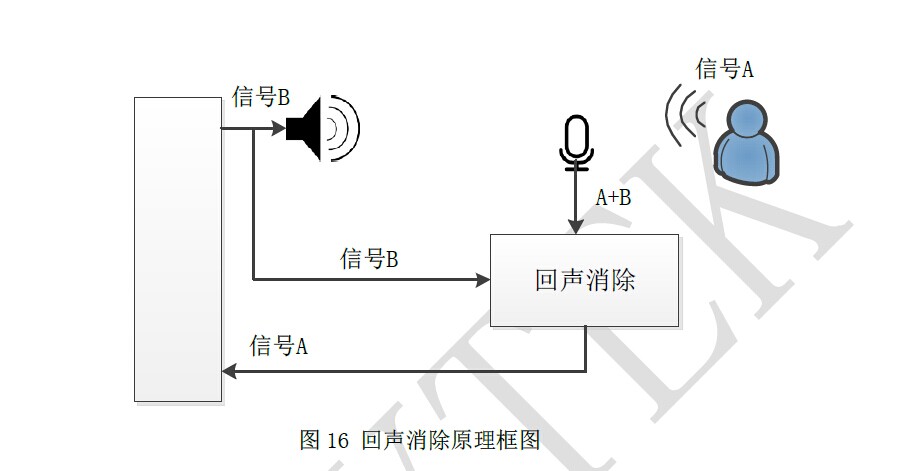
語音信號通過我們的介面送進語音引擎中,這段語音信號的質量其實是比較差的,這段語音有周圍的雜訊,機器本身雜訊,所以我們先要做的處理就是降噪、回聲消除、端點檢測,可能大家不是很理解回聲消除是怎麼抑制回聲的,我給個原理圖示大家應該就明白了:
做完了語音預處理之後,把相對比較純凈的信號發送給特徵提取部分,這個部分主要幹什麼呢?
我們人和人是不同的,膚色、身高、體重、樣子這些都是特徵,而語音部分我們提取什麼呢?信號頻率、振幅,這其實就是每個人音色不同的秘密所在,將這些特徵提取送到語音識別引擎的聲學模型中去。它會自動匹配這些語音信息最大概率的發音漢字。說白了就是這個讀音是哪個漢字的讀法,然後把這個漢字單獨拎出來。
其實什麼是聲學模型呢?簡單來講就是一種刻畫(拼音讀法)韻母a、o、e,聲母b、p、m這些的模型,那這些模型是怎麼來的?它是怎麼知道這個字怎麼讀的呢?這個時候我們就需要輸入一些音頻訓練集了,例如我們正常說話一段話,同時輸入剛才說的那一段話的文本,機器會自動取出其中不同的因素,並且拿去繼續訓練模型,修正誤區。
這樣對於機器演算法來說,有了輸入和輸出,還能不斷優化自身模型。演算法是不是很神奇。這些不同因素數據會先進行預處理,例如百度就做了一定的加噪處理,這樣在雜訊環境下魯棒。
其中語音識別模塊除了聲學模型之外還有一個同等重要的模塊就是語言模塊,什麼叫語言模塊呢?就是刻畫文本和文本之間概率權重的。那麼語言模型是怎麼來的,假如我們要想做醫學領域的語言模型,那就要讓它去學習很多醫學術語,這個時候就需要我們準備這些術語做成一個詞表,但是同樣需要數據清洗,原始數據會有些垃圾,在做一些權重的正規化,並送到模型中去訓練,從而得出或者優化原有模型。簡單說你提前給醫學領域的專用術語背下來了,下次一聽到相關的語音你就能記起來這個專用術語。
例如【板藍根】,訓練之後一聽到這個語音就不會識別成【版爛根】
這樣我們最終就能得到這個語音識別的模型,並且我們可以通過繼續迭代來優化這個模型
既然模型有了,那怎麼看好還是差呢?有幾個方面來分辨。
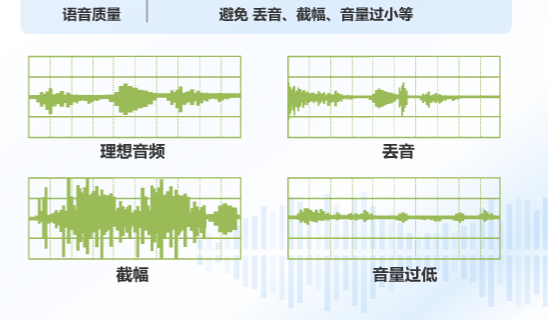
理想音頻就是識別質量較好的情況,但是現實生活中語音識別往往回因為各種情況導致識別效果不佳,比如丟音,比如你按下手機麥克風按鈕時,還沒有啟動錄音你就開始說話了,那沒啟動時說的語音就被丟棄了,這種情況識別就差很多了,什麼叫截幅呢?就是一般語音識別都是用兩個位元組來表示一個語音的取值範圍,當你的增益太大就會被自動截掉,識別的效果也較差了。
回過頭來,我們剛才所得到的語音訓練模型只是一種特定情況下得到的語音模型,不具備普適性。為何這麼說呢?
我們所得到的醫學領域模型,假設是用手機錄音採集的語料,那麼這個模型就是近場識別模型,一旦同樣的術語【板藍根】你用手機詢問就能回答正確,但是你一旦用音箱遠場詢問,那很可能就得出錯誤的回答,這叫聲學一致性。
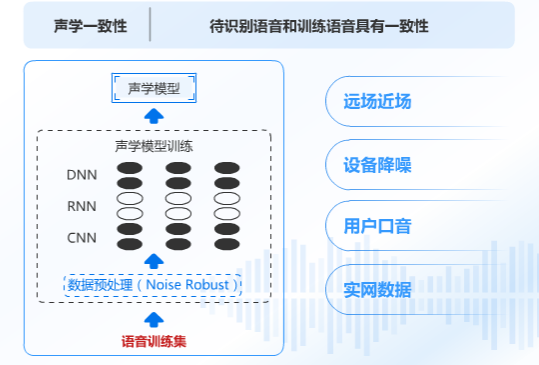
同樣,不同領域也需要文本一致性,你希望這個領域能多識別該領域的專業辭彙那就需要多訓練這個領域的核心辭彙,否則就會出現【板藍根】的情況。
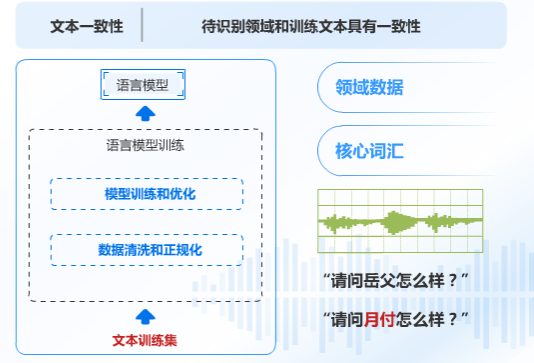
最後,通過不斷的獲取到不同的音頻數據、文本數據,並繼續迭代優化,我們會得到更好的模型,識別更準的效果。
這就是識別的細節,這也是一種科技的魅力,眾多步驟完成了我們看似簡單的動作。與其說機器的緊密不如說人類的身體系統更加複雜與奧妙。