
編輯導語:語音識別已經走進了大家的日常生活中,我們的手機、汽車、智能音箱均能對我們的語音進行識別。那麼什麼是語音識別呢?它又能應用於哪裡?該如何對其進行測試與運營維護呢?本文作者為我們進行了詳細地介紹。

現在人機語音交互已經成為我們日常生活的一部分,語音交互更自然,大大的提高了效率。上一篇文章我們聊了語音喚醒,這次我們繼續聊聊語音交互的關鍵步驟之一——語音識別。
一、什麼是語音識別
文字絕對算是人類最偉大的發明之一,正是因為有了文字,人類的文明成果才得以延續。
但是文字只是記錄方式,人類一直都是依靠聲音進行交流。所以人腦是可以直接處理音頻信息的,就像你每次聽到別人和你說話的時候,你就會很自然地理解,不用先把內容轉變成文字再理解。
而機器目前只能做到先把音頻轉變成文字,再按照字面意思理解。
微信或者輸入法的語音轉文字相信大家都用過,這就是語音識別的典型應用,就是把我們說的音頻轉換成文字內容。
語音識別技術(Automatic Speech Recognition)是一種將人的語音轉換為文本的技術。
概念理解起來很簡單,但整個過程還是非常複雜的。正是由於複雜,對算力的消耗比較大,一般我們都將語音識別模型放在雲端去處理。
這也就是我們常見的,不聯網無法使用的原因,當然也有在本地識別的案列,像輸入法就有本地語音識別的包。
二、語音識別的應用
語音識別的應用非常廣泛,常見的有語音交互、語音輸入。隨著技術的逐漸成熟和5G的普及,未來的應用範圍只會更大。
語音識別技術的應用往往按照應用場景進行劃分,會有私人場景、車載場景、兒童場景、家庭場景等,不同場景的產品形態會有所不同,但是底層的技術都是一樣的。
1. 私人場景
私人場景常見的是手機助手、語音輸入法等,主要依賴於我們常用的設備—手機。
如果你的手機內置手機助手,你可以方便快捷的實現設定鬧鐘,打開應用等,大大的提高了效率。語音輸入法也有非常明顯的優勢,相較於鍵盤輸入,提高了輸入的效率,每分鐘可以輸入300字左右。
2. 車載場景
車載場景的語音助手是未來的趨勢,現在國產電動車基本上都有語音助手,可以高效的實現對車內一些設施的控制,比如調低座椅、打開空調、播放音樂等。
開車是需要高度集中注意力的事情,眼睛和手會被佔用,這個時候使用語音交互往往會有更好的效果。
3. 兒童場景
語音識別在兒童場景的應用也很多,因為兒童對於新鮮事物的接受能力很高,能夠接受現在技術的不成熟。常見的兒童學習軟體中的跟讀功能,識別孩子發音是否準確,這就應用的是語音識別能力。
還有一些可以語音交互的玩具,也有ASR識別的部分。
4. 家庭場景
家庭場景最常見的就是智能音箱和智能電視了,我們通過智能音箱,可以語音控制家裡面的所有電器的開關和狀態;通過語音控制電視切換節目,搜索我們想要觀看的內容。
三、語音識別詳解
整個從語音識別的過程,先從本地獲取音頻,然後傳到雲端,最後識別出文本,就是一個聲學信號轉換成文本信息的過程。整個識別的過程如下圖:
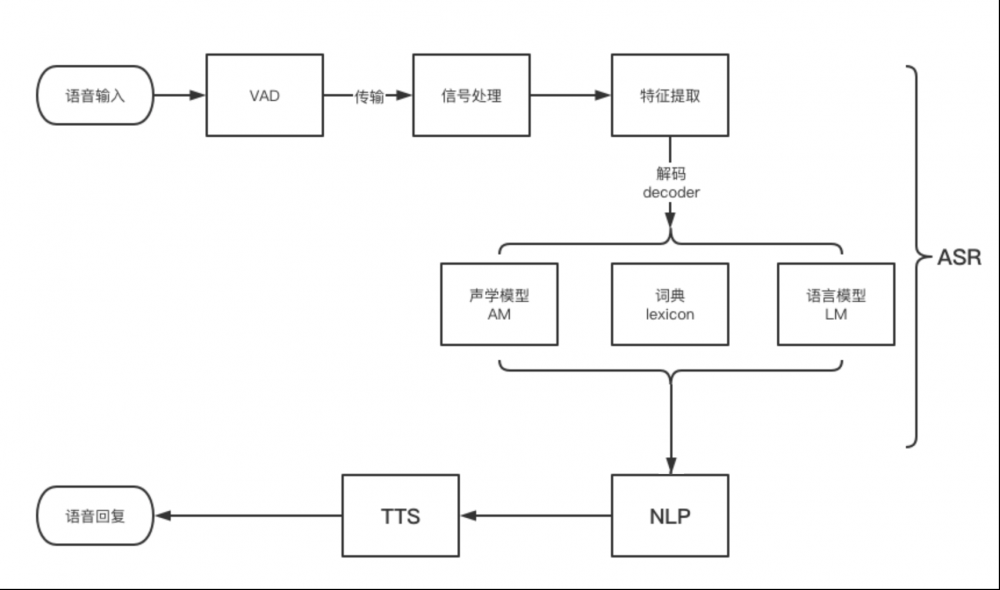
1. VAD技術
在開始語音識別之前,有時需要把首尾端的靜音切除,降低對後續步驟造成干擾,這個切除靜音的炒作一般稱為VAD。
這個步驟一般是在本地完成的,這部分需要用到信號處理的一些技術。
VAD(Voice Activity Detection):也叫語音激活檢測,或者靜音抑制。其目的是檢測當前語音信號中是否包含話音信號存在,即對輸入信號進行判斷,將話音信號與各種背景雜訊信號區分出來,分別對兩種信號採用不同的處理方法。
演算法方面,VAD演算法主要用了2-3個模型來對語音建模,並且分成雜訊類、語音類還有靜音類。目前大多數還是基於信噪比的演算法,也有一些基於深度學習(DNN)的模型。
一般在產品設計的時候,會固定一個VAD截斷的時間,但面對不同的應用場景,可能會要求這個時間是可以自定義的,主要是用來控制多長時間沒有聲音進行截斷。
比如小孩子說話會比較慢,常常會留尾音,那麼我們就需要針對兒童場景,設置比較長的VAD截斷時間;而成人就可以相對短一點,一般會設置在400ms-1000ms之間。
2. 本地上傳(壓縮)
人的聲音信息首先要經過麥克風整列收集和處理,然後再把處理好的音頻文件傳到雲端,整個語音識別模型才開始工作。
這裡的上傳並不是直接把收音到的音頻丟到雲端,而是要進行壓縮的,主要考慮到音頻太小,網路等問題,會影響整體的響應速度。從本地到雲端是一個壓縮➡上傳➡解壓的過程,數據才能夠到達雲端。
整個上傳的過程也是實時的,是以數據流的形式進行上傳,每隔一段時間上傳一個包。
你可以理解為每說一個字,就要上傳一次,這也就對應著我們常常看到的一個字一個字的往屏幕上蹦的效果。一般一句「明天天氣怎麼樣?」,會上傳大約30多個包到雲端。
一般考慮我們大部分設備使用的都是Wi-Fi和4G網路,每次上傳的包的大小在128個位元組的大小,整個響應還是非常及時的。

3. 信號處理
這裡的信號處理一般指的是降噪,有些麥克風陣列本身的降噪演算法受限於前端硬體的限制,會把一部分降噪的工作放在雲端。
像專門提供雲端語音識別能力的公司,比如科大訊飛、谷歌,自己的語音識別模型都是有降噪能力的,因為你不知道前端的麥克風陣列到底是什麼情況。
除了降噪以外可能還涉及到數據格式的歸一化等,當然有些模型可能不需要這些步驟,比如自研的語音識別模型,只給自己的機器用,那麼我解壓完了就是我想要的格式。
4. 特徵提取
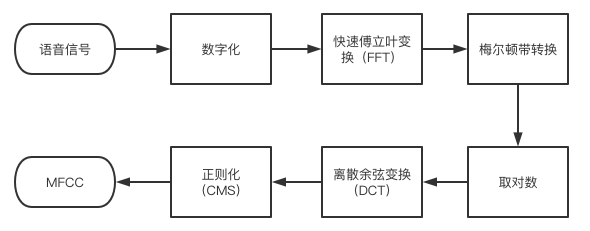
特徵提取是語音識別關鍵的一步,解壓完音頻文件后,就要先進行特徵提取,提取出來的特徵作為參數,為模型計算做準備。簡單理解就是語音信息的數字化,然後再通過後面的模型對這些數字化信息進行計算。
特徵提取首先要做的是採樣,前面我們說過音頻信息是以數據流的形式存在,是連續不斷的,對連續時間進行離散化處理的過程就是採樣率,單位是Hz。
可以理解為從一條連續的曲線上面取點,取的點越密集,越能還原這條曲線的波動趨勢,採樣率也就越高。理論上越高越好,但是一般10kHz以下就夠用了,所以大部分都會採取16kHz的採樣率。
具體提取那些特徵,這要看模型要識別那些內容,一般只是語音轉文字的話,主要是提取音素;但是想要識別語音中的情緒,可能就需要提取響度、音高等參數。
最常用到的語音特徵就是梅爾倒譜係數(Mel-scaleFrequency Cepstral Coefficients,簡稱MFCC),是在Mel標度頻率域提取出來的倒譜參數,Mel標度描述了人耳頻率的非線性特性。
5. 聲學模型(AM)
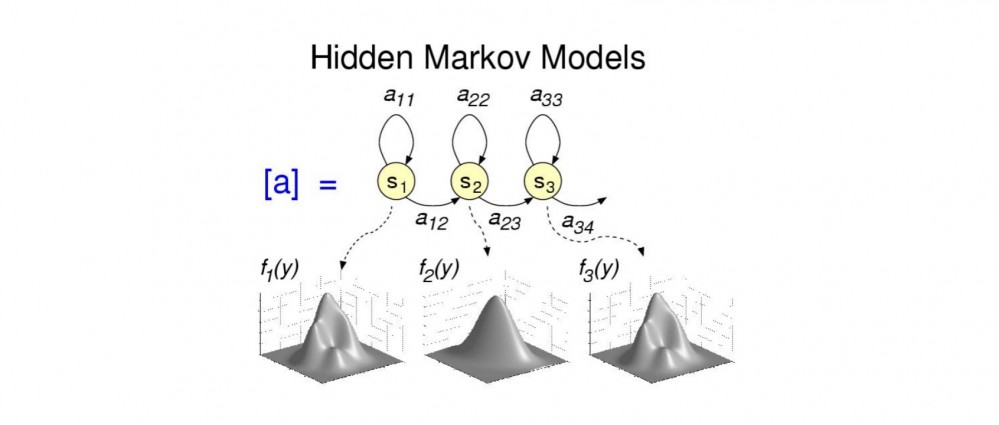
聲學模型將聲學和發音學的知識進行整合,以特徵提取模塊提取的特徵為輸入,計算音頻對應音素之間的概率。簡單理解就是把從聲音中提取出來的特徵,通過聲學模型,計算出相應的音素。
聲學模型目前的主流演算法是混合高斯模型+隱馬爾可夫模型(GMM-HMM),HMM模型對時序信息進行建模,在給定HMM的一個狀態后,GMM對屬於該狀態的語音特徵向量的概率分佈進行建模。
現在也有基於深度學習的模型,在大數據的情況下,效果要好於GMM-HMM。
聲學模型就是把聲音轉成音素,有點像把聲音轉成拼音的感覺,所以優化聲學模型需要音頻數據。
6. 語言模型(LM)
語言模型是將語法和字詞的知識進行整合,計算文字在這句話下出現的概率。一般自然語言的統計單位是句子,所以也可以看做句子的概率模型。簡單理解就是給你幾個字詞,然後計算這幾個字片語成句子的概率。
語言模型中,基於統計學的有n-gram 語言模型,目前大部分公司用的也是該模型。
還有基於深度學習的語言模型,語言模型就是根據一些可能的詞(詞典給的),然後計算出那些片語合成一句話的概率比較高,所以優化語言模型需要的是文本數據。

7. 詞典
詞典就是發音字典的意思,中文中就是拼音與漢字的對應,英文中就是音標與單詞的對應。
其目的是根據聲學模型識別出來的音素,來找到對應的漢字(詞)或者單詞,用來在聲學模型和語言模型建立橋樑,將兩者聯繫起來——簡單理解詞典是連接聲學模型和語言模型的月老。
詞典不涉及什麼演算法,一般的詞典都是大而全的,儘可能地覆蓋我們所有地字。詞典這個命名很形象,就像一本「新華字典」,給聲學模型計算出來的拼音配上所有可能的漢字。
整個這一套組成了一個完整的語音識別模型,其中聲學模型和語言模型是整個語音識別的核心,各家識別效果的差異也是這兩塊內容的不同導致的。
一般我們更新的熱詞,更新的都是語言模型中的內容,後面會詳細闡述。
四、語音識別相關內容
語音識別除了把語音轉換成文本以外,還有一些其他用處,這裡也簡單提一下。
1. 方言識別/外語識別
這裡把方言和外語一起討論,是因為訓練一個方言的語音識別模型,和訓練一個外語的模型差不多,畢竟有些方言聽起來感覺和外語一樣。
所以方言和外語識別,就需要重新訓練的語音識別模型,才能達到一個基本可用的狀態。
這裡就會遇到兩個問題:
- 從零開始訓練一個聲學模型需要大量的人工標註數據,成本高,時間長,對於一些數據量有限的小語種,就更是難上加難。所以選擇新語種(方言)的時候要考慮投入產出,是否可以介入第三方的先使用,順便積累數據;
- 除了單獨的外語(方言)識別之外,還有混合語言的語音識別需求,比如在香港,英文辭彙經常會插入中文短語中。如果把每種語言的語言模型分開構建,會阻礙識別的平滑程度,很難實現混合識別。

2. 語種識別(LID)
語種識別(LID)是用來自動區分不同語言的能力,將識別結果反饋給相應語種的語音識別模型,從而實現自動化的多語言交互體驗。簡單理解就是計算機知道你現在說的是中文,它就用中文回復你,如果你用英文和計算機說話,計算機就用英文回復你。
語種識別主要分三個過程:首先根據語音信號進行特徵提取;然後進行語種模型的構建;最後是對測試語音進行語種判決。
演算法層面目前分為兩類:一類是基於傳統的語種識別,一種是基於神經網路的語種識別。
傳統的語種識別包括基於HMM的語種識別、基於音素器的語種識別、基於底層聲學特徵的語種識別等。神經網路的語種識別主要基於融合深度瓶頸特徵的DNN語種識別,深度神經網路中,有的隱層的單元數目被人為地調小,這種隱層被稱為瓶頸層。
目前基於傳統的語種識別,在複雜語種之間的識別率,只有80%左右;而基於深度學習的語種識別,理論上效果會更好。當然這和語種的多樣性強相關,比如兩種語言的語種識別,和十八種語言的語種識別,之間的難度是巨大的。
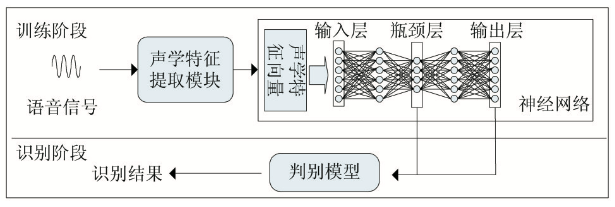
3. 聲紋識別(VPR)
聲紋識別也叫做說話人識別,是生物識別技術的一種,通過聲音判別說話人身份的技術。其實和人臉識別的應用有些相似,都是根據特徵來判斷說話人身份的,只是一個是通過聲音,一個是通過人臉。
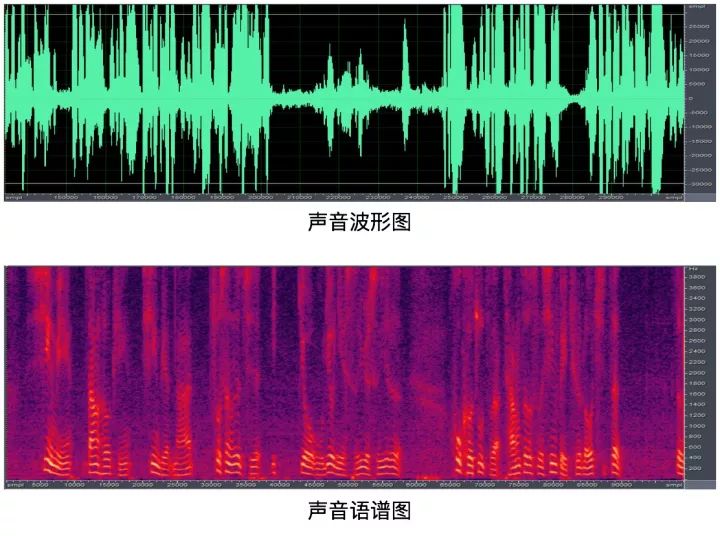
聲紋識別的原理是藉助不同人的聲音,在語譜圖中共振峰的分佈情況不同這一特徵,去對比兩個人的聲音,在相同音素上的發聲來判斷是否為同一個人。
主要是藉助的特徵有:音域特徵、嗓音純度特徵、共鳴方式特徵等,而對比的模型有高斯混合模型(GMM)、深度神經網路(DNN)等。
註:
- 共振峰:共振峰是指在聲音的頻譜中能量相對集中的一些區域,共振峰不但是音質的決定因素,而且反映了聲道(共振腔)的物理特徵。提取語音共振峰的方法比較多,常用的方法有倒譜法、LPC(線性預測編碼)譜估計法、LPC倒譜法等。
- 語譜圖:語譜圖是頻譜分析視圖,如果針對語音數據的話,叫語譜圖。語譜圖的橫坐標是時間,縱坐標是頻率,坐標點值為語音數據能量。由於是採用二維平面表達三維信息,所以能量值的大小是通過顏色來表示的,顏色深,表示該點的語音能量越強。
聲音識別也會有1to1、1toN、Nto1三種模式:
- 1to1:是判斷當前發聲和預存的一個聲紋是否一致,有點像蘋果手機的人臉解鎖,判斷當前人臉和手機錄的人臉是否一致;
- 1toN:是判斷當前發聲和預存的多個聲紋中的哪一個一致,有點像指紋識別,判斷當前的指紋和手機裡面錄入的五個指紋中的哪一個一致;
- Nto1:就比較難了,同時有多個聲源一起發聲,判斷其中那個聲音和預存的聲音一致,簡單理解就是所有人在一起拍照,然後可以精確的找到其中某一個人。當然也有NtoN,邏輯就是所有人一起拍照,每個人都能認出來。
除了以上的分類,聲紋識別還會區分為:
- 固定口令識別,就是給定你文字,你照著念就行,常見於音箱付款的驗證;
- 隨機口令識別,這個就比較厲害了,他不會限制你說什麼,自動識別出你是誰。
聲紋識別說到底就是身份識別,和我們常見的指紋識別、人臉識別、虹膜識別等都一樣,都是提取特徵,然後進行匹配。只是聲紋的特徵沒有指紋等特徵穩定,會受到外部條件的影響,所以沒有其他的身份識別常見。
4. 情緒識別
目前情緒識別方式有很多,比如檢測生理信號(呼吸、心率、腎上腺素等)、檢測人臉肌肉變化、檢測瞳孔擴張程度等。通過語音識別情緒也是一個維度,但是所能參考的信息有限,相較於前面談到的方法,目前效果一般。
通過語音的情緒識別,首先要從語音信息中獲取可以判斷情緒的特徵,然後根據這些特徵再進行分類;這裡主要藉助的特徵有:能量(energy)、音高(pitch)、梅爾頻率倒譜係數(MFCC)等語音特徵。
常用的分類模型有:高斯混合模型(GMM)、隱馬爾可夫模型(HMM)長短時記憶模型(LSTM)等。
語音情緒識別一般會有兩種方法:一種是依據情緒的不同表示方式進行分類,常見的有難過、生氣、害怕、高興等等,使用的是分類演算法;還有一種是將情緒分為正面和負面兩種,一般會使用回歸演算法。
具體使用以上哪種方法,要看實際應用情況。
如果需要根據不同的情緒,伴隨不同的表情和語氣進行回復,那麼需要使用第一種的分類演算法;如果只是作為一個參數進行識別,判斷當前說話人是消極還是積極,那麼第二種的回歸演算法就夠了。
五、語音識別如何測試
由於語言文字的排列組合是無限多的,測試語音識別的效果要有大數據思維,就是基於統計學的測試方法,最好是可以多場景、多人實際測試,具體要看產品的使用場景和目標人群。
另外一般還要分為模型測試和實際測試,我們下面談到的都是實際測試的指標。
1. 測試環境
人工智慧產品由於底層邏輯是計算概率,天生就存在一定的不確定性,這份不確定性就是由外界條件的變化帶來的,所以在測試語音識別效果的時候,一定要控制測試環境的條件。
往往受到以下條件影響:
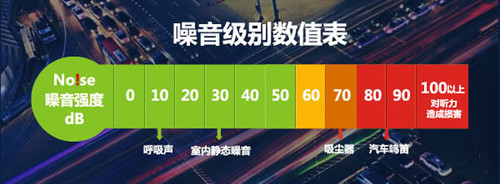
1)環境噪音
最好可以在實際場景中進行測試,如果沒有條件,可以模擬場景噪音,並且對噪音進行分級處理。
比如車載場景,我們需要分別測試30km/h、60km/h、90km/h、120km/h的識別效果,甚至需要加入車內有人說話和沒人說話的情況,以及開關車窗的使用情況——這樣才能反應真是的識別情況,暴露出產品的不足。
2)發音位置
發音位置同樣需要根據場景去定義 ,比如車載場景:我們需要分別測試主駕駛位置、副駕駛位置、後排座位的識別效果,甚至面向不同方向的發音,都需要考慮到。
3)發音人(群體、語速、口音、響度)
發音人就是使用我們產品的用戶,如果我們產品覆蓋的用戶群體足夠廣,我們需要考慮不同年齡段,不同地域的情況,比如你的車載語音要賣給香港人,就要考慮粵語的測試。
這裡不可控的因素會比較多,有些可能遇到之後才能處理。
2. 測試數據
整個測試過程中,一般我們會先準備好要測試的數據(根據測試環境),當然測試數據越豐富,效果會越好。
首先需要準備場景相關的發音文本,一般需要準備100-10000條;其次就是在對應的測試環境製造相應的音頻數據,需要在實際的麥克風陣列收音,這樣可以最好的模擬實際體驗;最後就是將音頻和文字一一對應,給到相應的同學進行測試。
關於測試之前有過一些有趣的想法, 就是準備一些文本,然後利用TTS生成音頻,再用ASR識別,測試識別的效果。這樣是行不通的,根本沒有實際模擬用戶體驗,機器的發音相對人來說太穩定了。

3. 詞錯率
詞錯率(WER):也叫字錯率,計算識別錯誤的字數占所有識別字數的比例,就是詞錯率,是語音識別領域的關鍵性評估指標。無論多識別,還是少識別,都是識別錯誤。
公式如下:
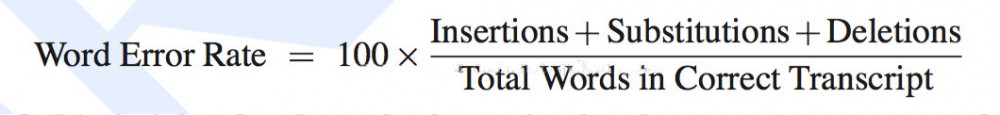
- Substitutions是替換數;
- Deletions是刪除數;
- Insertions是插入次數;
- Total Words in Correct Transcript是單詞數目。
這裡需要注意的是,因為有插入詞的存在,所以詞錯率可能會大於100%的,不過這種情況比較少見。
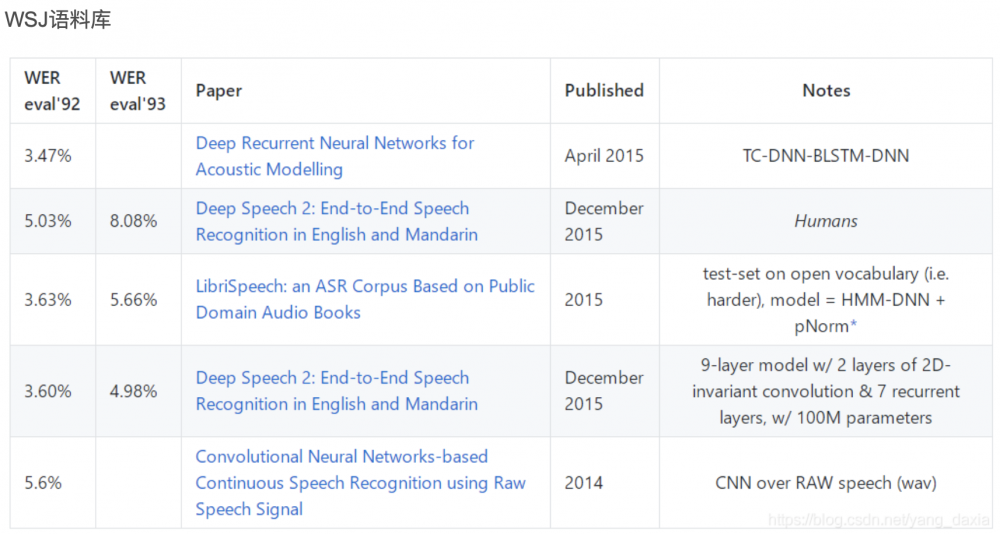
一般測試效果會受到測試集的影響,之前有大神整理過不同語料庫,識別的詞錯率情況,數據比較老,僅供參考:
4. 句錯率
句錯率(SWR):表示句子中如果有一個詞識別錯誤,那麼這個句子被認為識別錯誤,句子識別錯誤的個數佔總句子個數的比例,就是句錯率。

- # of sentences with at least one word error是句子識別錯誤的個數;
- total # of sentences是總句子的個數。
一般單純測模型的話,主要以詞錯率為關鍵指標;用戶體驗方面的測試,則更多偏向於句錯率。因為語音交互時,ASR把文本傳給NLP,我們更關注這句話是否正確。
在實際體驗中,句子識別錯誤的標準也會有所不同,有些場景可能需要識別的句子和用戶說的句子完全一樣才算正確,而有些場景可能語意相近就算正確,這取決於產品的定位,以及接下來的處理邏輯。
比如語音輸入法,就需要完全一樣才算正確,而一般閑聊的語音交互,可能不影響語意即可。
六、後期如何運營維護
在實際落地中,會頻繁的出現ASR識別不對的問題,比如一些生僻詞,阿拉伯數字的大小寫,這個時候就需要通過後期運營來解決。
一句話或者一個詞識別不對,可能存在多種原因;首先需要找到識別不對的原因,然後再利用現有工具進行解決。一般會分為以下幾種問題:
1. VAD截斷
這屬於比較常見的問題,就是機器只識別了用戶一部分的語音信息,另一部分沒有拾到音。
這個和用戶的語速有很大關係,如果用戶說話比較慢的,機器就容易以為用戶說完了,所以會產生這樣的問題。
一般的解決方案分為兩種:第一種是根據用戶群體的平均語速,設置截斷的時間,一般400ms差不多;第二種是根據一些可見的細節去提示用戶,注意說話的語速。
2. 語言模型修改
這類問題感知最強,表面上看就是我說了一句話,機器給我識別成了一句不想相關的內容:這種問題一方面和用戶想要識別的詞相關,一方面和用戶的發音有關,我們先不考慮用戶的發音。
一般生僻詞會遇到識別錯誤的問題,這主要是模型在訓練的時候沒有見過這類的內容,所以在識別的時候會比較吃力。遇到這種問題,解決方案是在語言模型裡面加入這個詞。
比如說:我想看魑魅魍魎,訓練的時候沒有「魑魅魍魎」這四個字,就很可能識別錯誤,我們只需要在語言模型中加入這個詞就可以。一般工程師會把模型做成熱更新的方式,方便我們操作。
有的雖然不是生僻字,但還是會出現競合問題,競合就是兩個詞發音非常像,會互相衝突。一般我們會把想要識別的這句話,都加到語言模型。
比如:帶我去宜家商場,這句話裡面的「宜家」可能是「一家」,兩個詞之間就會出現競合。如果客戶希望識別的是「宜家」,那我們就把 「帶我去宜家商場」整句話都加入到語言模型之中。

3. 干預解決
還有一類識別錯誤的問題,基本上沒有解決方法。
雖然我們上面說了在語言模型中加詞,加句子,但實際操作的時候,你就會發現並不好用;有些詞就算加在語言模型裡面,還是會識別錯誤,這其實就是一個概率問題。
這個時候我們可以通過一些簡單粗暴的方式解決。
我們一般會ASR模型識別完成之後,再加入一個干預的邏輯,有點像NLP的預處理。在這步我們會將識別錯誤的文本強行干預成預期的識別內容,然後再穿給NLP。
比如:我想要一個switch遊戲機,而機器總是識別成「我想要一個思維詞遊戲機」,這個時候我們就可以通過干預來解決,讓「思維詞」=「switch」,這樣識別模型給出的還是「我想要一個思維詞遊戲機」。
我們通過干預,給NLP的文本就是「我想要一個switch遊戲機」。
![]()
七、未來展望
目前在理想環境下,ASR的識別效果已經非常好了,已經超越人類速記員了。但是在複雜場景下,識別效果還是非常大的進步空間,尤其雞尾酒效應、競合問題等。
1. 強降噪發展
面對複雜場景的語音識別,還是會存在問題,比如我們常說的雞尾酒效應,目前仍然是語音識別的瓶頸。針對複雜場景的語音識別,未來可能需要端到端的深度學習模型,來解決常見的雞尾酒效應。
2. 語音鏈路整合
大部分公司會把ASR和NLP分開來做研發,認為一個是解決聲學問題,一個是解決語言問題。其實對用戶來講,體驗是一個整體。
未來可以考慮兩者的結合,通過NLP的回復、或者反饋,來動態調整語言模型,從而實現更準確的識別效果,避免競合問題。
3. 多模態結合
未來有可能結合圖像演算法的能力,比如唇語識別、表情識別等能力,輔助提高ASR識別的準確率。比如唇語識別+語音識別,來解決複雜場景的,聲音信息混亂的情況。
目前很多演算法的能力都是一個一個的孤島,需要產品經理把這些演算法能力整合起來,從而作出更準確的判斷。
八、總結
語音識別就是把聲學信號轉化成文本信息的一個過程,中間最核心的演算法是聲學模型和語言模型,其中聲學模型負責找到對應的拼音,語言模型負責找到對應的句子。
後期運營我們一般會對語言模型進行調整,來解決識別過程中的badcase。
通過聲音,我們可以做語種識別、聲紋識別、情緒識別等,主要是藉助聲音的特徵進行識別,其中常用的特徵有能量(energy)、音高(pitch)、梅爾頻率倒譜係數(MFCC)等。
未來語音識別必將會和自然語言處理相結合,進一步提高目前的事變效果,對環境的依賴越來越小。