

1 引用
Xiaodong Gu and Hongyu Zhang and Sunghun Kim. Deep code search. In Proceedings of the 40th International Conference on Software Engineering, 2018, 933–944.
2 摘要
為了實現程序功能,開發人員可以通過大規模搜索來重用以前編寫的代碼段和代碼庫。多年來,業界已經提出了許多代碼搜索工具來幫助開發人員。現有方法通常將源代碼視為文本文檔,並利用信息檢索模型來檢索與給定查詢匹配的相關代碼段。這些方法主要依靠源代碼和自然語言查詢之間的文本相似性。他們對查詢和源代碼的語義缺乏深刻的了解。
在本文中,我們提出了一種名為 CODEnn(代碼描述嵌入神經網路)的新型深層神經網路。 CODEnn 不是匹配文本相似性,而是將代碼段和自然語言描述共同嵌入到高維向量空間中,以使代碼段及其對應的描述具有相似的向量。使用統一的矢量表示,可以根據它們的矢量檢索與自然語言查詢相關的代碼段。還可以識別語義上相關的單詞,並且可以處理查詢中不相關的關鍵字/雜訊。
作為概念驗證應用程序,我們使用 CODEnn 模型實現了一個名為 DeepCS 的代碼搜索工具。我們根據從 GitHub 收集的大規模代碼庫經驗性地評估 DeepCS。實驗結果表明,我們的方法可以有效地檢索相關的代碼片段,並優於以前的技術。
3 技術介紹
在本文中,我們提出了一種名為 CODEnn(代碼描述嵌入神經網路)的新型深層神經網路。為了彌合查詢和源代碼之間的辭彙鴻溝,CODEnn 將代碼段和自然語言描述共同嵌入到高維向量空間中,以使代碼段及其對應的描述具有相似的向量。利用統一的矢量表示,可以根據它們的矢量來檢索與自然語言查詢語義相關的代碼段。 還可以識別語義上相關的單詞,並且可以處理查詢中不相關的關鍵字/雜訊。
使用 CODEnn,我們實現了代碼搜索工具 DeepCS。DeepCS 在來自 GitHub 的 1820 萬 Java 代碼段(以註釋方法的形式)上訓練了 CODEnn 模型。然後,它從代碼庫中讀取代碼片段,並使用經過訓練的 CODEnn 模型將其嵌入向量中。 最終,當用戶進行查詢時,DeepCS 會找到具有與查詢向量最接近的向量的代碼片段,並將其返回。
3.1 CODEnn:代碼搜索深度神經網路
受現有聯合嵌入技術的啟發,我們針對代碼搜索問題提出了一種名為 CODEnn(代碼描述嵌入神經網路)的新型深度神經網路。 圖 1 說明了 CODEnn 的總體架構。自然語言查詢和代碼段是異構的,無法根據其辭彙標記輕鬆匹配。 為了彌合差距,CODEnn 將代碼片段和自然語言描述共同嵌入到統一的向量空間中,以便將查詢和相應的代碼片段嵌入附近的向量中,並可以通過測量向量相似度進行匹配。
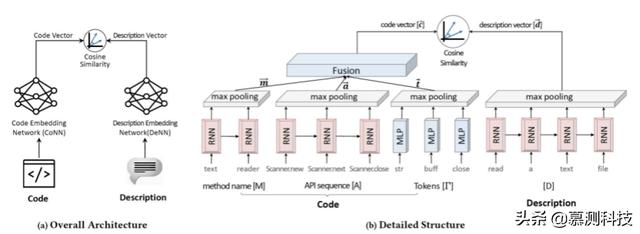
圖 1 CODEnn 的框架圖
聯合嵌入模型需要三個組件:嵌入函數和 ψ 以及相似性度量。 CODEnn 通過深度神經網路實現了這些組件。神經網路由三個模塊組成,每個模塊對應於聯合嵌入的一個組成部分:代碼嵌入網路(CoNN),用於將源代碼嵌入向量中。描述嵌入網路(DeNN),用於將自然語言描述嵌入向量中。 相似度模塊,用於測量代碼和描述之間的相似度。
3.2 DEEPCS:基於深度學習的代碼搜索
在本節中,我們對 DeepCS 進行介紹,這是一種基於所提出的 CODEnn 模型的代碼搜索工具。對於給定的自然語言查詢,DeepCS 推薦前 K 個最相關的代碼段。圖 2 顯示了其整體架構。它包括三個主要階段:離線培訓,離線代碼嵌入和在線代碼搜索。我們首先收集大規模的代碼片段,即帶有相應描述的 Java 方法。我們從方法中提取子元素(包括方法名稱,標記和 API 序列)。然後,我們使用語料庫來訓練 CODEnn 模型(離線訓練階段)。對於用戶希望從其搜索代碼段的給定代碼庫,DeepCS 提取搜索代碼庫中每個 Java 方法的代碼元素,並使用經過訓練的 CODEnn 模型的 CoNN 模塊計算代碼矢量(離線嵌入階段)。最後,當用戶查詢到達時,DeepCS 首先使用 CODEnn 模型的 DeNN 模塊計算查詢的向量表示,然後返回其向量與查詢向量接近的代碼片段(在線代碼搜索階段)。從理論上講,我們的方法可以搜索以任何編程語言編寫的源代碼。在本文中,我們將範圍限制為 Java 代碼。
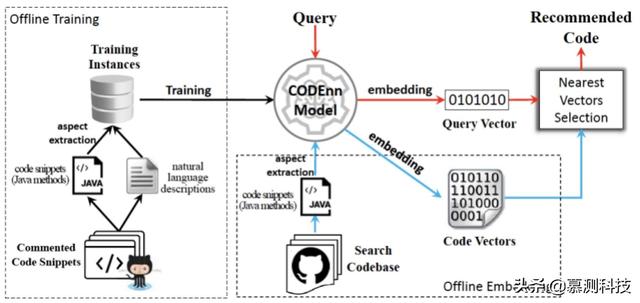
圖 2 DeepCS 的整體工作流程
我們按照所述的方法,使用上一節中描述的大規模語料庫來訓練 CODEnn 模型。 CODEnn 模型的詳細實現如下:我們將雙向 LSTM(RNN 的最新子類)用於 RNN 實現。所有 LSTM 在每個方向上都有 200 個隱藏單元。我們將單詞嵌入的維數設置為 100。CODEnn 具有兩種類型的 MLP:用於嵌入單個令牌的嵌入 MLP 和用於組合不同方面的嵌入的融合 MLP。對於嵌入的 MLP,我們將隱藏單元的數量設置為 100,對於融合的 MLP,我們將其設置為 400。CODEnn 模型通過小批量亞當演算法進行訓練。我們將批處理大小(即每批實例數)設置為 128。為訓練神經網路,我們將辭彙表的大小限制為訓練數據集中最常用的 10,000 個單詞。我們基於兩個開源深度學習框架 Keras 和 Theano 構建模型。我們在配備一個 Nvidia K40 GPU 的伺服器上訓練模型。訓練持續 500 個紀元,持續約 50 個小時。
給定用戶的自由文本查詢,DeepCS 通過訓練有素的 CODEnn 模型返回相關的代碼段。 它首先為搜索代碼庫中的每個代碼段(即 Java 方法)計算代碼矢量。然後,它選擇並返回查詢向量中前 K 個最接近向量的代碼段並將其返回。 更具體地說,在搜索開始之前,DeepCS 使用代碼的 CoNN 模塊將代碼庫中的所有代碼段嵌入向量中。
3.4 實驗評估
在本節中,我們將通過實驗評估 DeepCS。我們還將 DeepCS 與相關的代碼搜索方法進行了比較。
為了更好地評估 DeepCS,我們的實驗是在與訓練語料庫不同的搜索代碼庫上進行的。 從搜索代碼庫中檢索與用戶查詢匹配的代碼段。實際上,搜索代碼庫可以是組織的本地代碼庫,也可以是從開源項目創建的任何代碼庫。為了構建搜索代碼庫,我們選擇在 GitHub 中具有至少 20 星的 Java 項目。與訓練語料庫不同,它們被單獨考慮並且包含所有代碼(包括那些沒有 Javadoc 註釋的代碼)。總共有 9,950 個項目。我們從這些項目中選擇所有 16,262,602 種方法。對於每種 Java 方法,我們提取一個方法名稱,API 序列,令牌三元組以生成其代碼向量。
為了進行比較,我們使用了 CodeHow 和基於 Lucene 的工具進行對比實驗,我們對 CodeHow 和基於 Lucene 的工具使用與評估 DeepCS 相同的實驗設置
結果表明,DeepCS 產生的搜索結果通常比 Lucene 和 CodeHow 的更相關。圖 3a 顯示了三種方法的 FRank 的統計摘要。符號「 +」表示每種方法獲得的平均 FRank 值。對於在返回的前 10 個結果中未能獲得相關結果的查詢,我們保守地將 FRank 視為 11。我們觀察到 DeepCS 的平均 FRank 為 3.5,比 CodeHow(5.5)和 Lucene(6.0)的平均 FRank 小,從而獲得了更多相關的結果。 DeepCS 的 FRank 值集中在 1 到 4 的範圍內,而 CodeHow 和 Lucene 產生的方差更大,而相關的結果更少。圖 3b,3c 和 3d 顯示了當 k 分別為 1、5 和 10 時三種方法的 Precision@k 的統計量。我們觀察到,與 CodeHow 和基於 Lucene 的工具相比,DeepCS 的總體精度值更高。為了檢驗統計顯著性,我們使用 Wilcoxon 符號秩檢驗(p <0.05)比較 DeepCS 和所有相關查詢的兩種相關方法之間的 FRank 和 Precision@k。對於在返回的前 10 個結果中未能獲得相關結果的查詢,我們保守地將 FRank 視為 11。 DeepCS 與 Lucene 和 CodeHow 進行比較的 p 值均小於 0.05,表明 DeepCS 相對於相關方法的改進具有統計意義。。
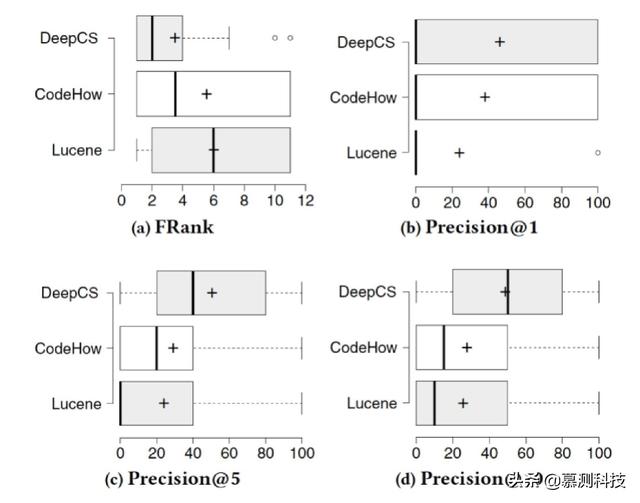
圖 3 三種代碼搜索方法的統計比較
通過比較實驗可以發現,DeepCS 的另一個優勢與關聯搜索有關。也就是說,它不僅查找具有匹配關鍵字的代碼段,而且還推薦沒有匹配關鍵字但在語義上相關的代碼段。這很重要,因為它會大大增加搜索範圍,尤其是在代碼庫較小的情況下。此外,開發人員還需要多種用途的代碼片段。關聯搜索為開發人員提供了更多的代碼片段選項供學習。傳統的基於 IR 的方法只能匹配包含諸如 xml,object 和 read 之類的關鍵字的代碼片段。但是,如圖所示,即使在結果中不存在關鍵字,DeepCS 也會成功識別查詢語義並返回 xml 反序列化的結果。相比之下,CodeHow 僅返回包含讀取,對象和 xml 的代碼段,從而縮小了搜索範圍。因此表明 DeepCS 通過理解語義而不只是匹配關鍵字來搜索代碼。類似地,一行中的 arraylist 的查詢初始化返回包含「new ArrayList」的代碼段,儘管該代碼段不包含關鍵字初始化。另外,假如搜索時播放歌曲,DeepCS 不僅返回具有匹配關鍵字的代碼片段,而且還建議使用與語義相關的單詞(例如音頻和語音)推薦結果。
我們提出了一種名為 CODEnn 的新型深度神經網路用於代碼搜索。CODEnn 不會匹配文本相似性,而是學習源代碼和自然語言查詢的統一向量表示,以便可以根據它們的向量來檢索與查詢語義相關的代碼片段。作為概念驗證應用程序,我們基於提出的 CODEnn 模型實現了代碼搜索工具 DeepCS。 我們的實驗研究表明,該方法是有效的,並且優於相關方法。將來,我們將研究源代碼的更多方面,例如控制結構,以更好地表示源代碼的高級語義。 我們設計的深度神經網路也可能使其他軟體工程問題受益,例如錯誤定位。
4 本文主要貢獻
據我們所知,我們是第一個提出基於深度學習的代碼搜索的。我們工作的主要貢獻如下:我們提出了一種新型的深度神經網路 CODEnn,以學習源代碼和自然語言查詢的統一矢量表示形式。我們開發了 DeepCS,這是一種利用 CODEnn 檢索給定自然語言查詢的相關代碼段的工具。我們使用大規模代碼庫對 DeepCS 進行了經驗評估。
致謝
感謝國家重點研發計劃課題:基於協同編程現場的智能實時質量提升方法與技術(2018YFB1003901)和國家自然科學基金項目:基於可理解信息融合的人機協同移動應用測試研究(61802171)支持!
本文由南京大學軟體學院 2018 級碩士生段定翻譯轉述。