
本文作者通過Knn演算法進行了一次用戶判斷預測的流程,文章為作者根據自身經驗所做出的總結,希望通過此文能夠加深你對Knn演算法的認識。

knn演算法簡介
K最近鄰(k-Nearest Neighbor,KNN)分類演算法,是一個理論上比較成熟的方法,也是最簡單的機器學習演算法之一。knn的基本思路是:如果一個樣本在特徵空間中的k個最相似(即特徵空間中最鄰近)的樣本中的大多數屬於某一個類別,則該樣本也屬於這個類別。
如下圖所示,如何判斷綠色圓應該屬於哪一類,是屬於紅色三角形還是屬於藍色四方形?
如果K=3,由於紅色三角形所佔比例為2/3,綠色圓將被判定為屬於紅色三角形那個類
如果K=5,由於藍色四方形比例為3/5,因此綠色圓將被判定為屬於藍色四方形類。
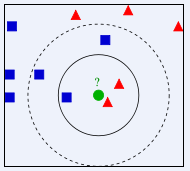
由於KNN最鄰近分類演算法在分類決策時只依據最鄰近的一個或者幾個樣本的類別來決定待分類樣本所屬的類別,而不是靠判別類域的方法來確定所屬類別的,因此對於類域的交叉或重疊較多的待分樣本集來說,KNN方法較其他方法更為適合。
因此,k值的選擇、距離度量以及分類決策規則是k近鄰演算法的三個基本要素。
真實業務場景
某公司存在有一些數據樣本(500*5矩陣),是關於人群屬性的一些特徵,希望通過已知數據的特徵,推測出部分目標數據的性質,假如特徵向量包含:
- 平均每日遊戲時長-game time
- 異性朋友數-female friends
- 周末在家時長-stay-in time
- 用戶接受類型-attr(attr是目標判斷屬性,同時也是標記屬性)
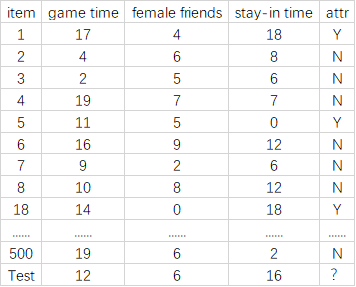
問題:我們需要根據已知的這些屬性,判斷最後一個樣本的屬性是「Y」還是「N」
數據特徵分析
我們所拿到的這批數據是500*5的矩陣,以平均每日遊戲時長,異性朋友數,周末在家時長為軸,將不同屬性的點用不同顏色區分,利用matplotlib繪製散點圖,最終效果如圖。
由於這些測試數據在空間的分佈非常集中,所以對於需要驗證的點(紅,綠兩點),我們很容易區分出這些點的屬性
結合本次的業務場景,我們將通過前三種特徵的空間分佈,對attr屬性進行預測
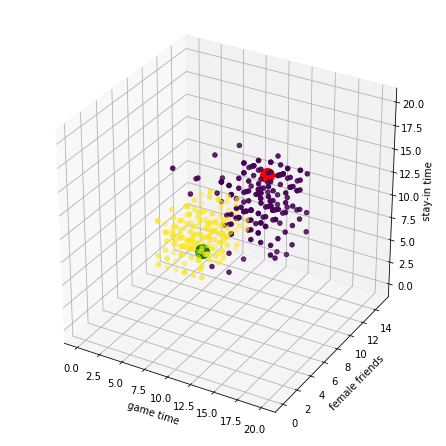
具體演算法
在三維空間中,我們可以直觀判斷,那在具體的演算法實現中,可以考慮使用
n維空間的歐氏距離:
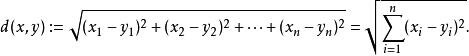
通過以上公式,我們能對多維度數據進行分析,得到目標與各點的距離。
同時,細心的讀者肯定考慮到,我們已知的這些特徵,存在量級之間的差異,所以我們通常需要通過歸一化特徵值,對消除不同量級造成的影響。因此,我們選用0-1標準化(0-1 normalization)對原始數據的線性變換。
0-1標準化:
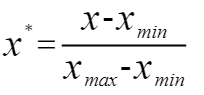
在通過以上兩步對數據預處理完成後,我們將所得的距離進行排序,並選取合適的K值對目標數據進行預測。
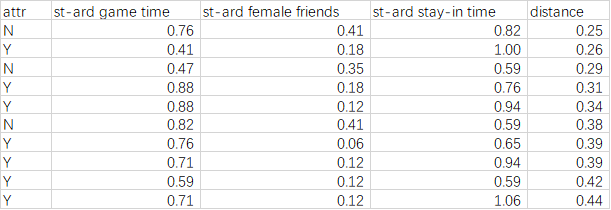
在此選擇k=10(僅舉例),可以發現,前10項中Y出現的次數最多,因此我們可以認為目標數據的值為Y。
knn演算法總結
在數據分析團隊確定好數據特徵后,對相應數據進行收集及清洗,對各數據特徵進行歸一化處理(視具體業務場景定,或需特徵考慮權重),完成以上流程后,進行以下通用流程:
- 計算測試數據與各個訓練數據之間的距離;
- 按照距離的遞增關係進行排序;
- 選取距離最小的K個點;
- 確定前K個點所在類別的出現頻率;
- 返回前K個點中出現頻率最高的類別作為測試數據的預測分類。
最後,我們簡單總結一下Knn的適用場景
- 數據已存在標記特徵,Knn是監督演算法
- 樣本數在100k以下,由於演算法會對每個目標值進行多維度距離計算,所以樣本過大可能超負荷
- 樣本非文本,或可轉化為數值
以上便是通過Knn演算法進行了一次用戶判斷預測的流程,文中所展示內容均為模擬數據,且選擇了其中最簡單的判斷屬性。如文中有遺漏及不足,請各位指出。